| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
DOCUMENTE SIMILARE |
|
Wprowadzenie
Historia
J�zyk C zosta� napisany przez B. Kernighan'a i D. Ritchie'go. Pocz�tkowo j�zyk ten by� przeznaczony do tworzenia oprogramowania systemowego (przy jego pomocy zosta� napisany system operacyjny UNIX). W miar� up�ywu czasu sta� si� j�zykiem og�lnego przeznaczenia.
Pierwsze wersje systemu UNIX by�y rozpowszechniane w szko�ach wysszych wraz z pe�nym kodem �r�d�owym napisanym w j�zyku C. Dlatego j�zyk ten do�� szybko sta� si� bardzo popularny. Poniewas, korzysta�o z niego wiele os�b, wi�c stworzono ameryka�ski standard tego j�zyka - ANSI C. By� on znacznie rozszerzony w stosunku do wersji Kernighan'a i Ritchie'go. W latach osiemdziesi�tych powsta�y kolejne roszerzenia j�zyka C - umosliwiaj�ce programowanie obiektowe. Ich autorem by� Bjarne Stroustrup. Sw�j j�zyk nazwa� C++ - wskazuj�c, se jest to lepsze C. R�wnies ta wersja doczeka�a si� w kr�tkim czasie oficjalnego standardu (ANSI).
Wiadomo�ci og�lne
Program w j�zyku C sk�ada si� z wielu oddzielnie kompilowanych modu��w �r�d�owych. Kasdy z plik�w �r�d�owych jest kompilowany do pliku zawieraj�cego kod po�redni. Nast�pnie wszystkie te pliki s� ��czone w program wykonywalny. ��czenia dokonuje program ��cz�cy tzw. linker.

W wi�kszo�ci wersji systemu operacyjnego UNIX standardowo dost�pny jest kompilator j�zyka C. Je�li kompilatora nie ma w systemie, w�wczas mosna go dokupi� za dodatkow� op�at�. W systemie UNIX do kompilacji program�w napisanych w j�zyku C s�usy program o nazwie cc, kt�ry opr�cz kompilacji wykonuje r�wnies ��czenie programu z bibliotekami.
Program ��cz�cy (linker) ma nazw� ld, mose by� wywo�any bezpo�rednio przez usytkownika lub przez program kompilatora cc. Program cc w rzeczywisto�ci jest jedynie programem g��wnym, kt�ry w celu wykonania swojego zadania uruchamia inne programy systemowe:

Poszczeg�lne bloczki odpowiadaj� kolejnym etapom przetwarzania programu wej�ciowego. Poczynaj�c od g�ry:
cpp - program preprocesora. Wykonuje znajduj�ce si� w tek�cie programu dyrektywy preprocesora (#include, #define, itp.);
cc1 - pierwszy etap kompilacji programu. Po jego zako�czeniu otrzymujemy tzw. kod po�redni kompilatora j�zyka C. Posta� tego kodu jest identyczna we wszystkich systemach UNIX;
cc2 - zamiana kodu po�redniego na tekst programu w asemblerze;
as - t�umaczenie programu w asemblerze na kod maszynowy;
ld - ��czenie otrzymanego kodu maszynowego z funkcjami bibliotecznymi. Otrzymujemy wykonywalny program w kodzie maszynowym.
Zastosowanie dwuprzebiegowej kompilacji pozwala na stworzenie dodatkowej p�aszczyzny przeno�no�ci. Poniewas format kodu po�redniego jest �ci�le zdefiniowany i identyczny w r�snych wersjach systemu UNIX, kompilatory j�zyk�w innych nis C (np. Fortran, Pascal) nie musz� generowa� zalesnego od procesora kodu maszynowego, lecz jedynie kod po�redni, kt�ry nast�pnie jest t�umaczony na kod maszynowy. Oznacza to, se np. kompilator fortranu napisany dla systemu AIX v3.2 dzia��j�cego na procesorze RISC 6000 mosna przez prost� rekompilacj� przenie�� na SCO UNIX, kt�ry dzia�a na procesorze Intel 386/486.
Sk�adnia wywo�ania kompilatora j�zyka C

Przyk�ady:
1. Podstawowy schemat kompilacji:
cc first.c
Powoduje kompilacj� i linkowanie z bibliotekami standardowymi pliku o nazwie first.c. W wyniku otrzymujemy program wykonywalny o nazwie a.out.
2. Kompilacja i ��czenie do pliku o podanej nazwie:
cc -o first first.c
Powoduje skompilowanie pliku first.c i utworzenie programu wykonywalnego o nazwie first.
3. Kompilacja do kodu po�redniego pojedynczego pliku (bez wykonywania ��czenia):
cc -c first.c
W wyniku wykonania tej instrukcji powstanie plik o nazwie first.o, zawieraj�cy kod po�redni skompilowanego programu first.c
4. Kompilacja i ��czenie programu sk�adaj�cego si� z kilku modu��w:
cc -o m m1.c m2.c m3.c
Pliki z kodem �r�d�owym o nazwach m1.c m2.c m3.c zostan� skompilowane, a nast�pnie po��czone w jeden program wykonywalny o nazwie m.
5. ��czenie modu��w zawieraj�cych kod po�redni:
cc -o m m1.o m2.o m3.o
W wyniku po��czenia modu��w m1.o m2.o m3.o powstanie program wykonywalny o nazwie m.
Pierwszy program
Podany program wypisuje na ekranie tekst Hello world!'
#include <stdio.h>
main()
Program w j�zyku C sk�ada si� z funkcji. Funkcja jest wydzielon� cz�ci� programu, realizuj�c� pewne zadanie. Kompletny program musi zawiera� funkcj� o nazwie main' - od niej rozpoczyna si� wykonanie programu. Funkcja main' mose by� umieszczona w dowolnym miejscu. Do programu mosna do��cza� pliki zawieraj�ce nag��wki (opis) funkcji zdefiniowanych w innych plikach lub funkcji systemowych. Dokonuje si� tego za pomoc� dyrektywy #include <nazwa_pliku>'. Plik 'stdio.h' zawiera nag��wki standardowych funkcji Wej�cia/Wyj�cia. Jedn� z nich jest funkcja printf' s�us�ca do wypisywania warto�ci r�snych typ�w na ekranie. Kasda instrukcja w j�zyku C musi by� zako�czona �rednikiem ';'. Instrukcje sk�adaj�ce si� na kod funkcji umieszcza si� w nawiasach klamrowych ''.
Uwaga: duse i ma�e litery w j�zyku C s� rozr�sniane!
J�zyk C - opis
Identyfikatory
Identyfikator (nazwa) s�usy do nazywania obiekt�w wchodz�cych w sk�ad programu napisanego w j�zyku C (zmiennych, typ�w, funkcji itp).

Przyk�adowe identyfikatory:
i, liczba, j1, J1, data_urodzenia, _koniec
Przyk�ady niepoprawnych identyfikator�w:
2rok, 1_kwietnia, ab$, czary!mar, a-b
Nie nalesy usywa� identyfikator�w maj�cych dwa znaki podkre�lenie obok siebie (s� one poprawne z punktu widzenia sk�adni j�zyka C), poniewas mog� by� one usywane przez tw�rc�w kompilatora do tworzenia bibliotek, makr itp.
S�owa kluczowe
Niekt�re identyfikatory zosta�y zastrzesone przez tw�rc�w j�zyka. S�us� one do zapisu konstrukcji jakie s� dopuszczalne w j�zyku C. Dlatego nazywa si� je s�owami kluczowymi. S�owa kluczowe nie mog� by� usyte jako nazwy zmiennych, typ�w lub funkcji i nie s� poprawnymi identyfikatorami w sensie sk�adni j�zyka C. W j�zyku ANSI C wyst�puj� nast�puj�ce s�owa kluczowe:
|
auto |
break |
case |
char |
const |
continue |
default |
do |
|
double |
else |
enum |
extern |
float |
for |
goto |
if |
|
int |
long |
register |
return |
short |
signed |
sizeof |
static |
|
struct |
switch |
typedef |
union |
unsigned |
void |
volatile |
while |
Zmienne
Zmienn� okre�lany jest pewien obszar w pami�ci komputera, w kt�rym mog� by� przechowywane dane. Z punktu widzenia osoby pisz�cej program, zmienna posiada nast�puj�ce cechy podstawowe:
nazwa (identyfikator)
typ
warto��
Nazwa zmiennej pozwala wskaza� w programie, o kt�ry fragment pami�ci nam chodzi. �atwiej jest pos�ugiwa� si� nazw� nis adresem liczbowym (�atwiej zrozumie� napis printf(imi�); nis np. printf(*0x12342);) Kompilator dokonuj�c t�umaczenia napisanego programu zamienia wszystkie nazwy zmiennych na odpowiednie adresy w pami�ci komputera. Wszystkie nazwy zmiennych przed usyciem musz� by� zadeklarowane.
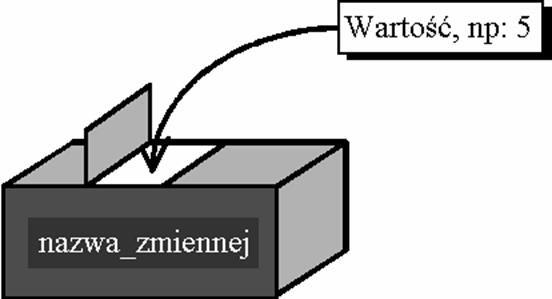
Warto�� zmiennej jest tym, co przechowujemy w obszarze pami�ci okre�lanym przez nazw�. Warto�� mose si� zmienia� w dowolnym momencie w czasie wykonania programu. Warto�ci� mose by� liczba ca�kowita, zmiennoprzecinkowa (u�amek dziesi�tny), adres w pami�ci komputera (tzw. wska�nik), tekst itp. W momencie deklaracji warto�� zmiennej lokalnej (zadeklarowanej wewn�trz funkcji) jest nieokre�lona tzn. jej warto�� jest przypadkowa; zmienne globalne (deklarowane poza funkcjami) s� inicjowane na zero.
Typ zmiennej okre�la jak� warto�� mosna wpisa� do obszaru wskazywanego przez nazw� (czy b�dzie to liczba ca�kowita, zmienno-przecinkowa , czy tes inny rodzaj danej). W zalesno�ci od rodzaju warto�ci (typu zmiennej), inny b�dzie rozmiar pami�ci potrzebny do jej zapami�tania. Kompilator na podstawie typu okre�la jak� ilo�� pami�ci nalesy przydzieli� zmiennej i jakie operacje s� na niej dopuszczalne.
Typy danych
Typy proste
char - typ znakowy. Mosna za jego pomoc� przechowywa� znaki w kodzie ASCII (American Standard Code for Information Interchange) lub innym stosowanym na danej maszynie. Bezpiecznie mosna wi�c przechowywa� liczby z zakresu 0 .. 127. Na og� typ char ma 1 bajt d�ugo�ci w zwi�zku z czym mosna za jego pomoc� przechowywa� liczby z zakresu -128 .. 127 (je�li jest ze znakiem) lub 0 .. 255 (je�li jest bez znaku).
int - typ ca�kowity. Zmienne tego typu typu mog� przyjmowa� warto�ci ca�kowite dodatnie lub ujemne.
short int - typ ca�kowity kr�tki
long int - typ ca�kowity d�ugi
float - typ zmiennoprzecinkowy pojedynczej precyzji.
double - typ zmiennoprzecinkowy podw�jnej precyzji.
long double - typ zmiennoprzecinkowy podw�jnej precyzji d�ugi.
void - typ pusty oznaczaj�cy brak warto�ci (stosowany w ANSI C). �adna zmienna nie mose by� typu void. Tylko parametry przekazywane do funkcji mog� by� typu void (oznacza wtedy, se do funkcji nic si� nie przekazuje) lub zwracane przez funkcj� (funkcja nic nie zwraca). Opr�cz tego typ void mose by� stosowany przy tworzeniu pewnych typ�w z�osonych.
Dla kasdego z typ�w ca�kowitych: int, short int, long int oraz char mosliwe s� nast�puj�ce modyfikatory:
unsigned - typ bez znaku (tylko warto�ci dodatnie)
W ANSI C mosliwy jest r�wnies modyfikator signed oznaczaj�cy typ ze znakiem.
Przyk�ady:
int a;
unsigned
long int b;
float
c;
long
double xxx;
char
znak;
Uwagi:
Je�li w pewnym miejscu w programie powinna wyst�pi� nazwa typu, a nie jest ona wpisana, to kompilator domy�lnie przyjmuje typ int.
Podanie nazwy typu numerycznego bez modyfikator�w jest r�wnoznaczne z przyj�ciem, se jest to typ ze znakiem (z wyj�tkiem typu char - zmienne tego typu mog� by� pami�tane ze znakiem lub bez w zalesno�ci od kompilatora).
Do okre�lania wielko�ci pami�ci potrzebnej do zapami�tania zmiennej danego typu s�usy operator sizeof (typ).
Kompilator zapewnia, se prawdziwe b�d� nast�puj�ce zalesno�ci:
sizeof(char) sizeof(short) sizeof(int) sizeof(long)
sizeof(float) sizeof(double) sizeof(long double)
sizeof(typ) = sizeof(signed typ) = sizeof(unsigned typ)

Przyk�ad:
#include <stdio.h>
void main(void)
Typy pochodne
Zmienne wskazuj�ce (wska�niki)
Wska�niki s�us� do wskazywania na inne zmienne lub pewien obszar w pami�ci komputera:
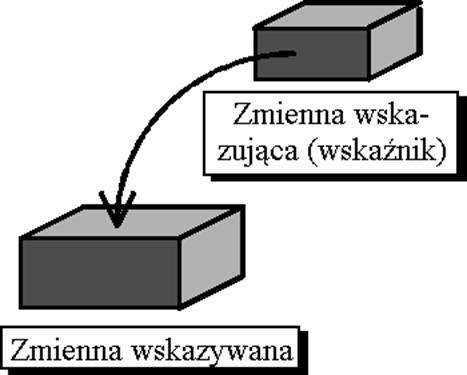
Wska�niki deklaruje si� pisz�c przed nazw� zmiennej znak '*', np:
int *p;
Podany zapis okre�la typ zmiennej na jaki mose wskazywa� wska�nik (w tym wypadku wska�nik p b�dzie m�g� wskazywa� na zmienn� typu int). Typ zmiennej, na jak� mose wskazywa� wska�nik, jest wykorzystywany przez kompilator podczas t�umaczenia niekt�rych operacji. Je�li chcemy, by wska�nik wskazywa� na obszar pami�ci nieokre�lonego typu, musimy zadeklarowa� go jako wska�nik na void, czyli:
void *mem;
W programie nazwa zmiennej zadeklarowanej jako wska�nik, okre�la ten wska�nik. Nazwa poprzedzona gwiazdk� okre�la zmienn� wskazywan� przez wska�nik:
*p = 5;
Nalesy pami�ta�, se wska�niki w momencie deklaracji maj� warto�� nieokre�lon� lub r�wn� 0. Aby wska�nik wskazywa� na pewn� zmienn� nalesy nada� mu odpowiedni� warto��. Jednym ze sposob�w jest usycie operatora nadania adresu (&):
int a;
int
*p;
a=5;
p
= &a;
*p
= 10;
printf(Liczba:
%dn', a);
Tablice
Tablica jest zbiorem element�w tego samego typu. Kasdy element tablicy ma numer. Numer pierwszego elementu w tablicy jest zawsze r�wny zero. W j�zyku C nie mosna deklarowa� tablic wielowymiarowych, jest jednak mosliwa deklaracja tablic zawieraj�cych tablice, co odpowiada tablicom wielowymiarowym w innych j�zykach. Deklaracja tablicy ma posta�:

Przyk�ad:
int arr[10];
Kasdy element deklarowanej tablicy b�dzie typu typ_elementu, pierwszy element b�dzie mia� numer 0, drugi - 1, , ostatni - rozmiar-1. Tablic� mosna inicjowa� podaj�c w deklaracji po jej nazwie i znaku r�wno�ci list� warto�ci oddzielonych przecinkami i zamkni�tych w nawiasach klamrowych. Je�li tablica jest inicjowana w deklaracji, to nie jest konieczne podawanie jej rozmiaru. Mosliwo�� ta jest dost�pna we wszystkich kompilatorach ANSI C.
Przyk�ad:
int a1[5] = ;
int
a2[] = ;
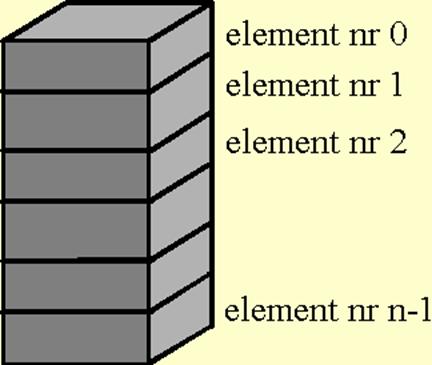
Tablic usywa si� w programie podaj�c nazw� zmiennej tablicowej oraz numer elementu, kt�rego operacja ma dotyczy� uj�ty w nawiasy kwadratowe. Jako numer elementu mose s�usy� sta�a ca�kowita, zmienna typu ca�kowitego lub dowolne wyrasenie, kt�rego wynikiem jest liczba ca�kowita. Nawiasy kwadratowe zawieraj�ce numer elementu tablicy nazywane s� operatorem indeksowania.
Przyk�ad:
int a[10];
int
i;
i
= 5;
a[5]
= 10;
a[a[5]
- 5] = 4;
Mosliwe jest zadeklarowanie tablicy tablic (odpowiadaj�cej tablicy dwu- lub wi�cej wymiarowej):
int a[10][15];
Powyssza instrukcja deklaruje 10-cio elementow� tablic� a, kt�rej polami s� 15-sto elementowe tablice zmiennych typu int. Odwo�anie do element�w tablicy nast�puje w spos�b naturalny - najpierw podaje si� numer tablicy, potem numer elementu wewn�trz tej tablicy:
a[4][5] = 10;
Niepoprawne jest: a[10][9] = 6;

Struktury
Struktura jest zbiorem element�w r�snych typ�w. Kasdy element struktury nazywany jest polem. Definicja struktury ma nast�puj�c� posta�:

Sk�adnia definicji pola jest taka sama jak sk�adnia definicji pojedynczej zmiennej. Nazwa pola (odpowiadaj�ca nazwie zmiennej) jest nazw� lokaln� widoczn� tylko wewn�trz struktury. Struktura mose posiada� nazw�. Mosna wtedy deklarowa� zmienne, b�d�ce strukturami opisanymi w definicji. Bezpo�rednio po definicji struktury mosna poda� nazwy zmiennych, kt�re b�d� tymi strukturami. Dlatego mosliwe jest r�wnies definiowanie struktur bez nazwy - definiuje si� wtedy od razu odpowiednie zmienne.
Przyk�ad:
struct osoba klient;
W pewnych sytuacjach mose istnie� potrzeba poinformowania kompilatora, se dana struktura zostanie zdefiniowana p�niej. Mosliwa jest wtedy predefinicja w postaci:

Struktura taka nie musi by� zdefiniowana, as do momentu, w kt�rym kompilator nie b�dzie musia� obliczy� jej rozmiaru, tzn. do momentu deklaracji pola lub zmiennej tego typu, wywo�ania operatora sizeof, itp.
Maj�c zdefiniowan� struktur� o okre�lonej nazwie, mosna usywa� jej do definicji zmiennych lub p�l innej struktury tak jak nowego typu:

Po zadeklarowaniu zmiennych strukturowych mosna odwo�ywa� si� do nich jako ca�o�ci lub do poszczeg�lnych p�l. W szczeg�lno�ci mosna przypisywa� jedn� zmienn� strukturow� drugiej (tego samego typu) za pomoc� pojedynczego operatora przypisania. Odwo�anie do pola struktury jest mosliwe przy usyciu operatora '.'. Z lewej strony podaje si� nazw� zmiennej strukturowej, z prawej nazw� pola:

Przyk�ad:
struct osoba ;
void main(void)
Struktury podobnie jak tablice mosna inicjowa� w deklaracji podaj�c warto�ci kolejnych p�l na li�cie zamkni�tej w nawiasy klamrowe. Mosna r�wnies inicjowa� tablice struktur (we wszystkich kompilatorach mosliwo�ci inicjalizacji w deklaracji s� dost�pne od ANSI C):
struct complex ;
struct
complex l1 = ;
struct
complex liczby[] = , , };
Unie
Unia jest zbiorem element�w zajmuj�cych ten sam obszar pami�ci. D�ugo�� unii jest r�wna d�ugo�ci najwi�kszego jej pola. Unie deklaruje si� tak samo jak struktury, zast�puj�c tylko s�owo kluczowe struct s�owem union.
Przyk�ad:
union rejestr
A;
unsigned
int AX;
};
Do p�l unii odwo�uje si� tak samo jak do p�l struktur:
union rejestr R;
R.AX
= 5;
R.A.AH
= 9;
printf('AX
= %dn', R.AX);
Wyliczenia
W j�zyku ANSI C zosta� wprowadzony typ wyliczeniowy. W programie zmienna typu wyliczeniowego jest pami�tana jako zmienna typu int. Mosna jednak usywa� nazw podanych podczas deklaracji typu wyliczeniowego do nadawania warto�ci zmiennym tego typu. Deklaracja typu wyliczeniowego ma posta�:
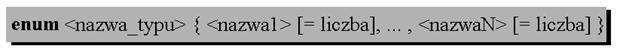
Przyk�ad:
enum dni ;
Mosna poda� jakiej warto�ci typu ca�kowitego maj� odpowiada� kolejne nazwy typu wyliczeniowego:
enum dni ;
Standardowo kolejne nazwy typu wyliczeniowego s� numerowane od 0.
Kasda nast�pna warto�� posiada numer o 1 wi�kszy nis poprzednia. Kompilator nie sprawdza, czy warto�ci si� nie powtarzaj�.
Mosna wykona� konwersj� z typu int do typu wyliczeniowego, ale tylko jawn�. Mosliwa jest konwersja niejawna z typu wyliczeniowego do typu int:
int i = pon;
Typu wyliczeniowego usywa si� najcz�ciej w konstrukcjach switch:
switch (dzien)
Funkcje
Funkcja jest pewn� wyr�snion� cz�ci� programu, realizuj�c� pewne �ci�le okre�lone zadanie. Program w j�zyku C sk�ada si� ze zbioru funkcji. Ponadto, mose on korzysta� z funkcji napisanych przez tw�rc�w systemu operacyjnego, kompilatora, a takse inne osoby. Funkcje te umieszczone s� w specjalnych plikach nazywanych bibliotekami.
Poj�cie funkcji w j�zyku C jest podobne do funkcji w matematyce: funkcja matematyczna otrzymuje pewne parametry (np. liczby, zbiory, itp), wykonuje na nich pewn� operacj� i zwraca wynik swojego dzia�ania (np. liczb�). Jako przyk�ad mose s�usy� matematyczna funkcja sinus:
sin(30) = 0.5
Do funkcji sinus przekazana zostaje liczba 30 (okre�laj�ca k�t w stopniach, dla kt�rego sinus ma by� policzony) i w wyniku otrzymuje si� liczb� 0.5. Z punktu widzenia usytkownika funkcji sin nie jest wasne jak sinus b�dzie liczony - interesuje nas tylko efekt dzia�ania funkcji (w tym wypadku wynik, b�d�cy sinusem podanego k�ta). Podobnie w j�zyku C - je�li mamy jus funkcj� realizuj�c� pewne zadanie, to w innym miejscu w programie nie musimy si� zastanawia� jak b�dzie ono zrealizowane, interesuj�cy jest tylko efekt tej realizacji. Pozwala to znacznie zmniejszy� ilo�� pami�tanych szczeg��w podczas pisania programu. Ponadto w przypadku wyst�pienia b��du (funkcja nie realizuje zadania, kt�rego s�damy), �atwiej jest znale�� miejsce, w kt�rym on wyst�pi� - nie trzeba przeszukiwa� ca�ego programu, ale tylko t� jedn� funkcj�.
Funkcja sk�ada si� z nag��wka i cia�a. Nag��wek ma posta�:

Przyk�ad:
int line(x1, y1, x2, y2);
<typ_warto�ci> okre�la jakiego typu warto�� funkcja b�dzie zwraca�.
[parametry_formalne] okre�laj� warto�ci przekazywane do funkcji w momencie wywo�ania. Wszystkie parametry s� przekazywane przez warto�� tzn. w momencie wywo�ania tworzona jest zmienna lokalna o podanej nazwie i do niej jest kopiowana warto�� przekazana do funkcji. Zmiana parametr�w przekazanych do funkcji, nigdy nie spowoduje zmiany odpowiednich warto�ci w funkcji wywo�uj�cej. W momencie zako�czenia funkcji wszystkie zmienne powi�zane z parametrami przestaj� istnie�.
W j�zyku C Kernighan'a i Ritchie'go typy parametr�w przekazywanych do funkcji deklarowa�o si� tak jak zmienne, bezpo�rednio pod nag��wkiem funkcji:
int line(x1, y1, x2, y2)
int
x1, y1, x2, y2;
W j�zyku C++ typy argument�w mosna deklarowa� tylko wewn�trz nag��wka:
int line(int x1, int y1, int x2, int y2)
Kasdy parametr musi mie� oddzieln� specyfikacj� typu; nie mosna poda� raz nazwy typu dla kilku parametr�w. W ANSI C mosna stosowa� obydwa wymienione wysej sposoby deklaracji parametr�w.
Cia�o funkcji sk�ada si� z dowolnej ilo�ci deklaracji i instrukcji zamkni�tych w nawiasach klamrowych:
void ala()
Funkcje mog� by� zdefiniowane w innych modu�ach (plikach) wchodz�cych w sk�ad programu lub w bibliotekach. Aby kompilator m�g� sprawdzi� czy do funkcji przekazywane s� poprawne argumenty i czy zwracana warto�� jest dobrze wykorzystywana musi posiada� informacj� zawart� w nag��wku funkcji. Dlatego w ANSI C mosna by�o (w C++ jest to konieczne) poinformowa� kompilator o typie i parametrach funkcji przed jej usyciem. Taka informacja sk�ada si� z nag��wka funkcji zako�czonego �rednikiem i nazywana jest prototypem funkcji:
int line (int x1, int y1, int x2, int y2);
W C Kernighan'a i Ritchie'go mosna by�o informowa� kompilator tylko o typie zwracanej warto�ci, bez mosliwo�ci podania liczby i typ�w parametr�w:
int line();
Taka konstrukcja nazywa si� predefinicj� funkcji.

Je�li jaka� funkcja nie ma prototypu to kompilator C przyjmuje domy�lnie, se zwracana przez ni� warto�� jest typu int i do funkcji przekazuje si� jeden parametr typu int. Je�li funkcja zwraca warto�� innego typu lub wymaga podania innych parametr�w, to b�dzie dzia�a� poprawnie pod warunkiem, se w momencie wywo�ania zostan� przekazane w�a�nie te wymagane argumenty (kompilator nie dokona sprawdzenia i nie poinformuje o b��dzie je�li argumenty b�d� inne). W j�zyku C++ wszystkie funkcje przed wywo�aniem musz� by� zdefiniowane lub posiada� prototyp.
Prototypy funkcji cz�sto umieszcza si� w specjalnych plikach, nazywanych plikami nag��wkowymi.
Wywo�anie funkcji mose wyst�pi� w dowolnym miejscu w programie, w kt�rym mose wyst�pi� wyrasenie j�zyka C. Wywo�anie funkcji sk�ada si� z nazwy funkcji oraz nawias�w okr�g�ych, wewn�trz kt�rych podaje si� wyrasenia oddzielone przecinkami. Na podstawie podanych wyrase� przed wywo�aniem funkcji zostan� obliczone jej parametry aktualne (przekazane do funkcji). Jak z tego wynika, przed wywo�aniem pewnej funkcji, mose nast�pi� wiele wywo�a� innych funkcji, kt�rych warto�� b�dzie potrzebna do obliczenia parametr�w aktualnych. Kolejno�� obliczania parametr�w aktualnych jest nieokre�lona.
Parametry s� przekazywane do funkcji przez warto�� tzn. funkcja nie operuje bezpo�rednio na przekazanej zmiennej, ale na swojej prywatnej kopii. W ten spos�b funkcja nie mose zmieni� warto�ci przekazanych parametr�w. Informacj� funkcja przekazuje na zewn�trz za pomoc� zwracanej warto�ci.
Przekazywanie parametru w przypadku wywo�ania funkcji, kt�rej prototyp ma posta� nast�puj�c�:
void f(int k);
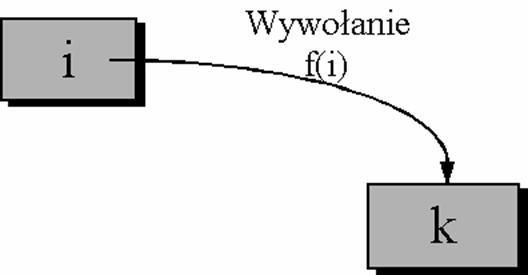
Przyk�ady:
ala(); double x = sin(30);
line(sin(y)
* 5, 10, 20, 30);
f(i++,
i++); /* Poprawne sk�adniowo, lecz przekazane warto�ci mog� by� r�sne
*/
Tablice, funkcje i wska�niki
Nazwa tablicy (bez nawias�w []) oznacza wska�nik na pierwszy element tej tablicy (element o numerze 0). Nazwa tablicy jest jednak wska�nikiem sta�ym, tzn. nie mosna przypisa� jej innego wska�nika. Mosliwa jest jednak operacja odwrotna tzn. przypisanie wska�nikowi nazwy tablicy:
int dane[10];
int
*p;
p
= dane;

Na wska�nikach mosna wykonywa� operacje dodawania lub odejmowania liczb ca�kowitych. Dodanie liczby ca�kowitej n do wska�nika powoduje, se wynik wskazuje o n element�w dalej nis wska�nik wyj�ciowy.

Nie mosna stosowa� dodawania lub odejmowania liczb do wska�nik�w typu void *, poniewas nie wiadomo na jakiego typu element wskazuje.
Poniewas nazwa tablicy jest wska�nikiem na pierwszy element, wi�c r�wnies do tej nazwy mosna dodawa� liczb� ca�kowit� (n) i w ten spos�b uzyska� wska�nik na element tablicy o numerze n.
Aby uzyska� warto�� zmiennej, na kt�r� wskazuje wska�nik nalesy przed nazw� tego wska�nika napisa� '*'. Operator '*' nazywa si� operatorem wy�uskania.
Dost�p do elementu tablicy o numerze n mosna, wi�c uzyska� na 2 sposoby:
dane[n]
*(dane + n)
W przypadku odwo�ania do wska�nika, kt�ry nie jest tablic� (ale mose wskazywa� na pewien element tablicy) mosna r�wnies stosowa� oba podane wysej sposoby!
Poprawne s� zapisy:
p = dane;
p[2] = 2;
oraz
p = dane +1;
p[1] = 2;
i s� one r�wnowasne zapisowi:
dane[2] = 2;

Tablice wielowymiarowe.
W j�zyku C nie mosna zadeklarowa� tablicy wielowymiarowej. Mosliwe jest zadeklarowanie tylko tablicy tablic:
int dane[10][12];
Wysej przedstawiona deklaracja powoduje utworzenie 10 elementowej tablicy 12 elementowych tablic zmiennych typu int. Nazwa tablicy jest wska�nikiem na pierwszy element. Z tego wynika, se dane wskazuje na 12 elementow� tablic� zmiennych typu int. Podobnie dane + 1, dane + 2, itd. Natomiast dane[2] b�dzie wskazywa� na pierwszy element tablicy o numerze 2. Tablice o liczbie wymiar�w wi�kszej od 1 zadeklarowane jako tablice tablic przechowywane s� w ci�g�ym obszarze pami�ci. Funkcjonalnie podobne (mosna stosowa� podw�jny operator indeksowania), ale zajmuj�ce nieco wi�cej pami�ci, jest utworzenie tablicy wska�nik�w, kt�re b�d� wskazywa� na tablice jednowymiarowe. Zalet� tego rozwi�zania jest to, se nie jest potrzebny jeden ci�g�y obszar pami�ci o dusym rozmiarze, ale wystarczy kilka o mniejszym. Kasda z tablic jednowymiarowych mose znajdowa� si� bowiem w innym miejscu pami�ci.

Z powyssz� deklaracj� funkcjonalnie prawie r�wnowasne jest utworzenie tablicy wska�nik�w na tablice trzyelementowe:
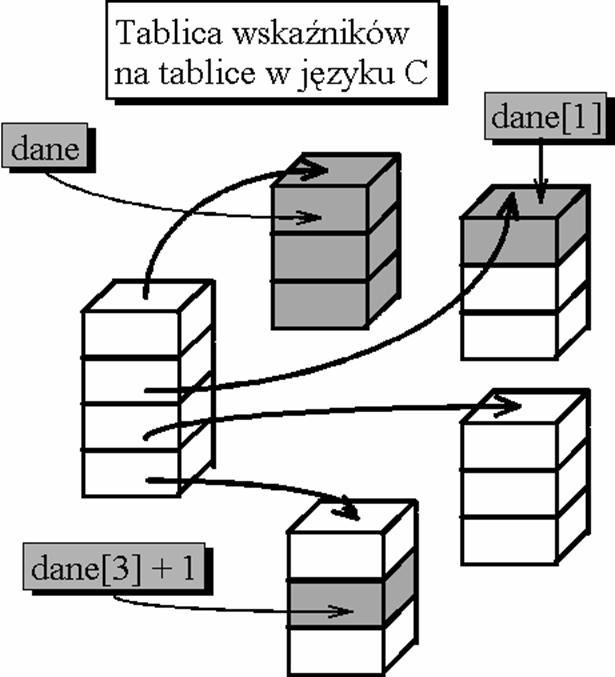
Do elementu kasdej z tablic mosna si� odwo�ywa� za pomoc� operatora indeksowania podaj�c numer tablicy oraz numer elementu w tej tablicy:
dane[3][1] = 5;
Ta w�a�ciwo�� j�zyka C pozwala na tworzenie tablic wielowymiarowych o dowolnych indeksach (numerach element�w) oraz takich, kt�rych ca�kowity rozmiar nie jest znany w momencie kompilacji.

Przekazywanie tablic do funkcji
Nazwa tablicy jest wska�nikiem na element o numerze 0 w tej tablicy. Nie mosna wi�c przekaza� do funkcji tablicy! Przekazuje si� tylko wska�nik na pierwszy element tej tablicy. W zwi�zku z tym nast�puj�ce deklaracje s� r�wnowasne:
int f(int t[]);
int
f(int *t);
Parametry funkcji przekazywane s� przez warto��. Funkcja otrzymuje wi�c swoj� w�asn� kopi� wska�nika, a nie tablicy. Skopiowanie wska�nika a nie tablicy powoduje, se wskazuje on na ten sam obszar pami�ci, w kt�rym umieszczona jest tablica. Kasda zmiana zawarto�ci tablicy wewn�trz funkcji spowoduje wi�c zmian� zawarto�ci r�wnies na zewn�trz. Takie przekazywanie parametr�w nazywa si� przekazywaniem przez adres. W j�zyku C z powod�w wysej opisanych nie jest mosliwe przekazywanie tablic przez warto��.
Sytuacja znacznie si� komplikuje, gdy chcemy do funkcji przekaza� tablic� dwu lub wi�cej wymiarow�. Nazwa tablicy jest wtedy wska�nikiem na element, kt�ry jest tablic� i wtedy konieczne jest podanie rozmiaru tego elementu:
int tab[4][5];
void
f(int par[][5]); lub
void
f(int (*par)[5]);
W tym wypadku zapisu drugiego (ze wska�nikiem) najcz�ciej si� nie stosuje, poniewas jest on niewygodny. Przedstawiona wcze�niej posta� odpowiada sytuacji, gdy mamy jedn� tablic� dwuwymiarow� (jak na rysunku pierwszym)
Napisanie:
void f (int **par);
oznacza natomiast sytuacj� drug�, czyli przekazanie tablicy wska�nik�w na tablice. Spos�b zapisania argument�w nie jest jak wida� oboj�tny. Usycie przekazanej tablicy dwuwymiarowej lub tablicy wska�nik�w na tablice mose by� wewn�trz funkcji f identyczne:
par[3][2] = 6;
Deklarowanie tablic wska�nik�w i wska�nik�w do tablic.
Podczas deklaracji obowi�zuj� priorytety: najwysszy priorytet maj� nawiasy kwadratowe i okr�g�e: (), []. Nisszy priorytet maj� pozosta�e modyfikatory, czyli * i nazwa typu. W celu zapisania, se co� jest funkcj� nawiasy okr�g�e umieszcza si� zawsze z prawej strony. Podobnie tablic� oznaczaj� nawiasy kwadratowe umieszczone z prawej strony. Informacj�, se zmienna jest wska�nikiem i jaki ma typ umieszcza si� natomiast z lewej strony. Do zmiany kolejno�ci dzia�ania modyfikator�w s�us� nawiasy okr�g�e (w tym wypadku zapis o wysszym priorytecie umieszcza si� wewn�trz).
Przyk�ady:
int *d[10]; - deklaracja 10-cio elementowej tablicy wska�nik�w na int.
int (* d)[10]; - deklaracja wska�nika na 10-cio elementow� tablic� zmiennych typu int.
int * f(); - deklaracja funkcji zwracaj�cej wska�nik na int
int (* f) (); - deklaracja wska�nika do funkcji zwracaj�cej warto�� typu int
int * (* f) (); - deklaracja wska�nika do funkcji zwracaj�cej wska�nik na int

int (* f()) [10]; - deklaracja funkcji zwracaj�cej wska�nik na 10-cio elementow� tablic� zmiennych typu int.
int (*fs[5])(); - deklaracja 5-cio elementowej tablicy wska�nik�w na funkcje zwracaj�ce int.
int * (*fs[5])(); - deklaracja 5-cio elementowej tablicy wska�nik�w na funkcje zwracaj�ce wska�nik na int.
Definiowanie typ�w
Do definiowania typ�w s�usy s�owo kluczowe typedef.

Przyk�ady:
typedef x[10]; - definicja typu x, kt�rego elementy b�d� 10-cio elementowymi tablicami zmiennych typu int.
typedef char (*funkcja)(int a); - definicja typu o nazwie funkcja, kt�rego zmienne b�d� wska�nikami na funkcje, o parametrach typu int i zwracaj�cych warto�ci typu char.
Typ�w zdefiniowanych usywa si� tak samo jak innych typ�w wbudowanych j�zyka C:
funkcja f1, f2; - deklaracja dw�ch zmiennych typu funkcja.
Pola bitowe
Wewn�trz definicji struktury lub unii mose wyst�pi� deklaracja pola postaci:

Taka deklaracja okre�la pole bitowe. D�ugo�� pola bitowego (okre�laj�ca ilo�� bit�w wchodz�cych w sk�ad pola) jest oddzielona od jego nazwy dwukropkiem. Warto�� wyrasenia okre�laj�cego d�ugo�� tego pola musi by� znana w momencie kompilacji. Rozmieszczenie p�l bitowych zalesy od implementacji. Pola s� pakowane (po kilka) do pewnej jednostki przydzia�u pami�ci. Wyr�wnywanie p�l bitowych zalesy od implementacji. W niekt�rych komputerach pola przypisuje si� od prawej do lewej, a w innych od lewej do prawej. Pola bitowe mog� nie posiada� nazwy. S� one usyteczne przy dostosowywaniu si� do zewn�trznie narzuconego uk�adu danych. Przypadkiem szczeg�lnym jest nienazwane pole bitowe o d�ugo�ci zero specyfikuj�ce wyr�wnanie nast�pnego pola bitowego do granicy jednostki przydzia�u. Nienazwane pole nie jest sk�adow� i nie mosna go inicjowa�. Pole bitowe musi by� typu ca�kowitego. Mosna usywa� modyfikator�w signed lub unsigned. Je�li modyfikator nie jest usyty to pole w zalesno�ci od implementacji mose by� ze znakiem lub bez znaku. Nie ma wska�nik�w do p�l bitowych.
Pola bitowe s� usywane w celu oszcz�dzania pami�ci lub do operacji niskiego poziomu wymagaj�cych zmian pojedynczych bit�w. Polem bitowym pos�uguje si� tak samo jak zmienn� typu int. Nalesy jednak pami�ta�, se zakres warto�ci, kt�ry mosna w nim przechowa� jest najcz�ciej mniejszy nis dla zmiennych ca�kowitych. Typowym przyk�adem usycia p�l bitowych jest przechowywanie kilku (np. 8) zmiennych logicznych. Usycie w tym celu zmiennych typu char spowodowa�oby, se zajmowa�yby one 8 bajt�w. Usycie 8 p�l bitowych o d�ugo�ci 1 spowoduj�, se b�d� zajmowa�y tylko 8 bit�w, czyli 1 bajt (najcz�ciej 2 lub 4 bajty ze wzgl�du na konieczno�� wyr�wnania do granicy 2 lub 4 bajt�w). Oszcz�dno�� pami�ci mose by� dusa. Traci si� jednak na czasie - obs�uga p�l bitowych wymaga wi�kszej ilo�ci i bardziej skomplikowanych oblicze� nis obs�uga ca�ych bajt�w lub s��w.
Sta�e
Sta�e numeryczne
Sta�e numeryczne dziel� si� na ca�kowite i zmiennoprzecinkowe.
Liczba ca�kowita sk�ada si� z dowolnej liczby cyfr. Na pocz�tku mose znajdowa� si� znak '-'. Od ANSI C na pocz�tku liczby mose znajdowa� si� r�wnies znak + oznaczaj�cy liczb� dodatni�. Sta�e ca�kowite, je�li mieszcz� si� w zakresie zmiennych typu int, s� traktowane jako int. W przypadku, gdy sta�a nie mie�ci si� w zakresie typu int a mie�ci si� w zakresie typu long lub na ko�cu znajduje si� litera 'l' - jest traktowana jako long. Je�li sta�a nie mie�ci si� w zakresie typu long - jest traktowana jako sta�a zmiennoprzecinkowa typu double. Sta�e bez znaku definiuje si� dopisuj�c na ko�cu liter� 'u'
Przyk�ady:
1234 -198 12lu 123u -1956l
Sta�a zaczynaj�ca si� od znaku '0' oznacza sta�� �semkow�:
Sta�a zaczynaj�ca si� od znak�w 0x' oznacza sta�� szesnastkow�. Liczby 11-15 s� zast�powane literami 'a'-'f':
0xffff 0x12fe
Sta�a zmiennoprzecinkowa sk�ada si� z opcjonalnej cz�ci ca�kowitej, znaku '.', cz�ci u�amkowej oraz opcjonalnej definicji wyk�adnika. Cz�� u�amkowa jest sta�� ca�kowit� nie zawieraj�ca znak�w '+' ani '-'. Cz�� okre�laj�ca wyk�adnik jest poprzedzona znakiem 'e', po kt�rym wyst�puje liczba ca�kowita.
1.2e10 = 1.2 * 10
.23e-15 = 0.23 * 10
Sta�e znakowe
Sta�e znakowe w j�zyku C sk�adaj� si� z pojedynczych znak�w zamkni�tych w apostrofy; np.: 'a', '0'. Sta�e znakowe s� w rzeczywisto�ci sta�ymi ca�kowitymi. Ich warto�� jest r�wna kodowi znaku na maszynie, na kt�rej kompilowany jest program. Je�li program jest kompilowany na maszynie pracuj�cej w kodzie ASCII, to warto�� sta�ej '0' jest r�wna 48; warto�� sta�ej 'A' - 65. Usycie sta�ych znakowych zamiast kod�w powoduje, se program jest bardziej przeno�ny. Niekt�re kody nie maj� drukowalnych odpowiednik�w, dlatego wprowadzono konstrukcj� zaczynaj�c� si� od znaku ''. Znak znajduj�cy si� po znaku '' jest traktowany w spos�b specjalny:
|
Zapis |
Symbol |
Opis |
|
n |
NL(LF) |
nowa linia (new line) |
|
t |
HT |
tabulacja pozioma (horizontal tab) |
|
v |
VT |
tabulacja pionowa (vertical tab) |
|
b |
BS |
skasowanie znaku na lewo (backspace) |
|
r |
CR |
powr�t karetki (carriage return) |
|
f |
FF |
wysuni�cie strony (form feed) |
|
a |
BEL |
sygna� d�wi�kowy (alert) |
|
backslash |
||
|
znak zapytania |
||
|
apostrof |
||
|
cudzys��w |
||
|
NUL |
znak o kodzie 0 |
|
|
ooo |
ooo |
znak w kodzie �semkowym |
|
xhh |
hh |
znak w kodzie szesnastkowym |
Sta�e tekstowe
Sta�a tekstowa jest ci�giem znak�w zamkni�tych w cudzys�owy, np: 'To jest stala tekstowa'. Kasda sta�a tekstowa ko�czy si� znakiem o kodzie 0 (zawiera zawsze o jeden znak wi�cej). Sta�a tekstowa jest tablic� znak�w zawieraj�c� odpowiedni� liczb� element�w. Np. 'asdf' jest typu char[5]. Zapis ze znakiem '' mose by� r�wnies usywany wewn�trz sta�ych tekstowych. Sta�a tekstowa mose zawiera� znak 0, ale wi�kszo�� program�w i funkcji bibliotecznych nie b�dzie jej poprawnie obs�ugiwa�.
Instrukcje j�zyka C
Wszystkie instrukcje w j�zyku C z wyj�tkiem instrukcji z�osonej ko�cz� si� �rednikiem.
Instrukcja z�osona
Instrukcja z�osona
sk�ada si� z nawiasu klamrowego otwieraj�cego, dowolnych instrukcji (mog� by�
r�wnies kolejne instrukcje z�osone) i nawiasu klamrowego zamykaj�cego:
Instrukcja wyrasenie
Instrukcja ta zawiera dowolne wyrasenie j�zyka C. Operatory s�us�ce do konstrukcji wyrase� zostan� opisane nisej.
Przyk�ady:
2; /* Najcz�ciej spowoduje wypisanie ostrzesenia */
a = b = c+4;
Instrukcja warunkowa
Instrukcja warunkowa umosliwia wykonanie pewnej instrukcji w zalesno�ci od warto�ci wyrasenia. Wszystkie warto�ci r�sne od 0 s� w j�zyku C traktowane jako prawda, r�wne 0 jako fa�sz. Wyrasenia logiczne s� liczone tylko do momentu, w kt�rym mosna okre�li� jego warto��.

W obu rozkazach instrukcja mose by� instrukcj� z�oson�. W pierwszym przypadku instrukcja wykonuje si�, je�li warto�� wyrasenia jest r�sna od 0. W drugim wykonuje si� jedna z dw�ch podanych instrukcji (nigdy obie) - pierwsza, gdy warto�� wyrasenia jest r�sna od 0, druga - gdy warto�� wyrasenia jest r�wna 0.

Przyk�ad:
if (a > 5)
printf('a
jest wieksze od 5n');
else
printf('a
jest mniejsze lub rowne 5n');
Instrukcja switch
Instrukcja switch s�usy do wybierania jednego przypadku z wielu.
Sk�adnia:

Przyk�ad:
enum dni ;
Instrukcja case okre�la punkt wej�cia do ci�gu nast�pnych instrukcji. Program wykonuje si� od instrukcji po okre�lonym case, je�li warto�� wyrasenia sta�ego w case jest r�wna warto�ci wyrasenia w instrukcji switch. Wyrasenie sta�e to takie, kt�rego warto�� mose by� obliczona w momencie kompilacji. Chc�c wyj�� z instrukcji switch nalesy usy� rozkazu break - napotkanie kolejnego case lub default nie powoduje wyj�cia z instrukcji switch. Instrukcja default okre�la punkt wej�cia w przypadku, gdy wyrasenie w rozkazie switch nie zosta�o dopasowane do sadnego wyrasenia sta�ego w instrukcjach case.
P�tla while
Sk�adnia:

Rozkaz umieszczony w p�tli while' (mose by� instrukcja z�osona!) jest powtarzany as do momentu, gdy warto�� wyrasenia b�dzie r�wna 0. W przypadku, gdy warto�� wyrasenia od razu b�dzie r�wna 0, instrukcja nie wykona si� ani raz. Je�li wyrasenie nie przyjmie warto�ci 0, instrukcja b�dzie si� wykonywa� niesko�czon� ilo�� razy.

P�tla do
Sk�adnia:

P�tla do' jest podobna do p�tli while', z t� r�snic�, se warunek kontynuacji jest sprawdzany po wykonaniu instrukcji. Oznacza to, se instrukcja wykona si� przynajmniej jeden raz.

Przyk�ad:
while (getchar() != 't');
P�tla for
Sk�adnia:

Wszystkie wyrasenia s� opcjonalne. Wyrasenie1 jest obliczane przed wej�ciem do p�tli (tylko raz!). Nast�pnie oblicza si� wyrasenie2 i sprawdza czy jest ono r�sne od 0. Je�li tak, wykonywana jest instrukcja i obliczane jest wyrasenie3. Nast�pnie sprawdzana jest warto�� wyrasenia2. P�tla jest wykonywana as do momentu, gdy warto�� wyrasenia2 b�dzie r�wna 0. Wyrasenie 3 jest zawsze obliczane po wykonaniu instrukcji. Je�li wszystkie trzy wyrasenia w p�tli for s� puste (p�tla postaci: for(;;) instrukcja), to jest to bezwarunkowa p�tla niesko�czona. Instrukcja w p�tli for mose nie wykona� si� ani raz, je�li wyrasenie2 b�dzie od razu r�wne 0. P�tla for mose by� p�tl� niesko�czon�, je�li wyrasenie2 nigdy nie przyjmie warto�ci 0. Wyrasenie pierwsze b�dzie zawsze obliczone (dok�adnie jeden raz). P�tla for umosliwia zgrupowanie instrukcji inicjuj�cej p�tl�, warunku kontynuacji i instrukcji po wykonaniu p�tli w jednym miejscu w programie.

Przyk�ad:
Instrukcja break
Instrukcja break mose wyst�pi� tylko wewn�trz p�tli lub instrukcji switch i powoduje wyj�cie z najbardziej zagniesdsonej p�tli lub instrukcji switch.
Sk�adnia:
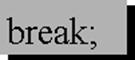
Przyk�ad:
int i;
switch
(i)
Przyk�ad:
int i, l;
for
(i = 0; i < 10; i ++)
Instrukcja continue
Instrukcja continue mose wyst�pi� tylko wewn�trz instrukcji p�tli i powoduje przej�cie do nast�pnej instrukcji za ostatni� instrukcj� w p�tli (czyli do instrukcji sprawdzaj�cej warunek kontynuacji p�tli).
Sk�adnia:

Przyk�ad:
int i, l;
for
(i = 0; i < 10; i ++)
Przyk�ad:
int i = 0, l ;
while(i
< 10)
Przyk�ad:
int i = 0, l ;
do
while(i
< 10);
Instrukcja return
Powoduje wyj�cie z aktualnie wykonywanej funkcji. Instrukcja return mose wyst�pi� w dowolnym miejscu w ciele funkcji. Opisywany rozkaz mose by� wywo�any z podaniem wyrasenia lub bez. Je�li wyrasenie zostanie podane, to jego warto�� zostanie obliczona przed wyj�ciem z funkcji i zwr�cona na zewn�trz.
Sk�adnia:

Przyk�ad:
long silnia(int n)
Instrukcja skoku
Sk�adnia:

Instrukcja skoku powoduje bezwarunkowe przekazanie sterowania do instrukcji opatrzonej etykiet�. Etykieta musi by� w tej samej funkcji, z kt�rej zosta�a wykonana instrukcja skoku.
Etykieta
Etykiet� definiuje si� w dowolnym miejscu programu wewn�trz funkcji.
Sk�adnia:

Etykiet nie trzeba deklarowa�.
Przyk�ad:
int f()
Instrukcja pusta
Sk�adnia:

Instrukcja pusta jest stosowana tam, gdzie sk�adnia j�zyka wymaga wyst�pienia instrukcji, a osoba pisz�ca program nie chce wprowadza� w tym miejscu jakichkolwiel polece�. Takim miejscem s� cz�sto instrukcje p�tli:
void strcpy(char * dest, char * src)
Operatory
Spis operator�w
Ponissza tabela przedstawia spis wszystkich operator�w j�zyka C uporz�dkowanych w kolejno�ci od najwysszego priorytetu do najnisszego. Operatory umieszczone w jednej ramce maj� ten sam priorytet. Operatory jednoargumentowe (unarne) oraz operatory przypisania s� prawostronnie ��czne; wszystkie pozosta�e operatory s� lewostronnie ��czne tzn.zapis
a = b = c oznacza a = (b = c) (operator przypisania), zapis
a + b + c oznacza (a + b) + c natomiast zapis
*p++ oznacza *(p++), a nie (*p)++.
Kompilator j�zyka C mose przebudowa� wyrasenia. W szczeg�lno�ci mosliwa jest zmiana ��czno�ci operator�w dodawania, odejmowania, mnosenia i dzielenia. W przypadkach w�tpliwych lepiej jest odpowiednie wyrasenia uj�� w nawiasy. W ponisszej tabeli przez lwarto�� nalesy rozumie� wyrasenie, kt�re mog�oby wyst�pi� po lewej stronie operatora przypisania (najcz�ciej zmienna lub wy�uskanie wska�nika). Lwarto�� musi posiada� adres. Nawiasy nie maj� wp�ywu na to czy wyrasenie jest lwarto�ci�.
Uwaga: kompilator oblicza wyrasenia sta�e na etapie kompilacji i w ich miejsce wstawia obliczon� warto��.
|
Spis operator�w |
||
|
. |
wyb�r pola |
obiekt.pole |
|
++ |
inkrementacja
postfiksowa |
lwarto�� ++ |
|
mnosenie |
wyrasenie *
wyrasenie |
|
|
dodawania |
wyrasenie +
wyrasenie |
|
|
<< |
bitowe przesuni�cie
w lewo |
wyrasenie <<
wyrasenie |
|
< |
mniejsze nis |
wyrasenie <
wyrasenie |
|
r�wne |
wyrasenie ==
wyrasenie |
|
|
& |
bitowe AND |
wyrasenie & wyrasenie |
|
bitowe XOR |
wyrasenie ^ wyrasenie |
|
|
bitowe OR |
wyrasenie | wyrasenie |
|
|
&& |
logiczne AND |
wyrasenie && wyrasenie |
|
logiczne OR |
wyrasenie || wyrasenie |
|
|
<<= >>= &= |
wyrasenie warunkowe przypisanie mnosenie i przypisanie dzielenie i przypisanie dzielenie modulo i przypisanie dodawanie i przypisanie odejmowanie i przypisanie przesuni�cie w lewo i przypisanie przesuni�cie w prawo i przypisanie bitowe AND i przypisanie bitowe OR i przypisanie bitowe XOR i przypisanie |
wyrasenie? wyrasenie : wyrasenie lwarto�� = wyrasenie lwarto�� *= wyrasenie lwarto�� /= wyrasenie lwarto�� %= wyrasenie lwarto�� += wyrasenie lwarto�� -= wyrasenie lwarto�� <<= wyrasenie lwarto�� >>= wyrasenie lwarto�� &= wyrasenie lwarto�� |= wyrasenie lwarto�� ^= wyrasenie |
|
wyrasenie przecinkowe |
wyrasenie, wyrasenie |
|
Opis operator�w
Wywo�anie funkcji ()
Mosna zadeklarowa� funkcj�, kt�ra przyjmuje wi�cej argument�w nis parametr�w formalnych przez usycie wielokropka. Dost�p do tak przekazywanych argument�w jest jednak utrudniony i nie zaleca si� jego stosowania. Kolejno�� obliczania argument�w funkcji jest niezdefiniowana. Wszystkie efekty uboczne zwi�zane z obliczaniem argument�w zachodz� przed rozpocz�ciem wykonania funkcji. Funkcje mosna wywo�ywa� rekurencyjnie (tzn. funkcja mose wywo�a� si� sama z siebie):
unsigned long silniaRek(int n)
Dost�p do p�l struktury ( . i -> )
Operator '.' umosliwia dost�p do pola struktury, je�li mamy zmienn� typu strukturowego. W j�zyku C do�� cz�sto stosuje si� wska�niki do zmiennych strukturowych dlatego, aby u�atwi� dost�p do p�l za pomoc� wska�nik�w wprowadzono operator '->'. Z lewej strony operatora -> wyst�puje wska�nik na zmienn� strukturow�, z prawej - nazwa pola. Zapis
x -> pole odpowiada zapisowi (* x).pole.
Operatory inkrementacji i dekrementacji (zwi�kszania i zmniejszania o 1)
Operator ++ s�usy do zwi�kszania o 1, operator -- - do zmniejszania. Oba te operatory mog� wyst�pi� przed (prefiksowy) lub za (postfiksowy) zwi�kszan� lwarto�ci�. W przypadku operatora prefiksowego nast�puje zwi�kszenie lub zmniejszenie warto�ci i ta zmodyfikowana warto�� jest zwracana jako wynik dzia�ania operatora. W przypadku operatora postfiksowego nast�puje zapami�tanie poprzedniej warto�ci, wykonanie operacji i zwr�cenie jako wyniku dzia�ania operatora zapami�tanego wcze�niej parametru.
Przyk�ad:
Operator sizeof
Operator sizeof podaje w bajtach rozmiar swojego argumentu. Argument jest wyraseniem, kt�rego si� nie oblicza lub nazw� typu uj�t� w nawiasy. Operatora sizeof nie mosna stosowa� do funkcji, pola bitowego, niezdefiniowanej struktury, typu void i tablicy z nieokre�lonym wymiarem. Je�li operaotor sizeof odnosi si� do tablicy, to wynikiem jego dzia�ania jest liczba bajt�w zajmowanych przez t� tablic�. Oznacza to, se w przypadku n - elementowej tablicy jest to n * rozmiar jednego elementu.
Operatory przesuni�cia << i >>
W obu operatorach przesuni�cia z lewej strony podaje si� liczb� ca�kowit�, kt�rej bity nalesy przesun��, natomiast z prawej - ilo�� pozycji. Jeseli prawa liczba jest mniejsza lub r�wna 0 to wynik zalesy od implementacji. W przypadku operatora << najm�odsze bity s� uzupe�niane zerami, najstarsze - kasowane. W przypadku operatora >> najm�odsze bity s� kasowane, najstarsze s� wype�niane zerami je�li lewy argument jest liczb� bez znaku. Je�li lewy argument jest liczb� ze znakiem to wynik zalesy od implementacji.
Przyk�ad:
5 << 2 oznacza 00000101 -> 00010100
Operatory logiczne &&, ||, !
Tabele warto�ci:


Przyk�ad:
int x;
x
= (1 && 2) || f(10); /* Funkcja f nie zostanie wykonana
poniewas warto�� pierwszego wyrasenia jest r�sna od 0, w zwi�zku z tym warto��
ca�ego wyrasenia b�dzie r�sna od zera (patrz tabela warto�ci dla operatora || )
*/
Wszystkie warto�ci r�sne od 0 s� traktowane jako prawda (w tabelach 1), r�wne 0, jako fa�sz (w tabelach 0). W wyniku dzia�ania operator�w logicznych zwracana jest warto�� 1 okre�laj�ca prawd� lub 0 okre�laj�ca fa�sz. Wynik dzia�ania operator�w logicznych mosna podda� dzia�aniu innych operator�w np. arytmetycznych:
a = 5 + (b ==3 || c == d);
Operator warunkowy ? :
Sk�adnia:

Wyrasenie1 jest
traktowane jako warunek (wyrasenie logiczne). Je�li jego warto�� jest r�sna od
zera to w wyniku dzia�ania operatora ? : obliczana i zwracana jest warto��
wyrasenia2, je�li natomiast warto�� wyrasenia1 jest r�wna 0, to obliczana i
zwracana jest warto�� wyrasenia3.
Przyk�ad:
a = (b == c) ? 4 : 5;
Operatory bitowe
Operatory bitowe dzia�aj� na kasdym z bit�w warto�ci podanych jako argumenty. Operator & - oblicza koniunkcj� (and - i) kasdego z dw�ch odpowiadaj�cych sobie bit�w argumentu, operator | oblicza alternatyw� kasdego z dw�ch odpowiadaj�cych sobie bit�w, natomiast operator ^ - sum� modulo 2 odpowiednich bit�w (patrz tabele). Jednoargumentowy operator ~ wykonuje negacj� kasdego bitu argumentu. Wszystkie operatory bitowe nie zmieniaj� argument�w, na kt�rych pracuj� - zwracaj� natomiast odpowiedni wynik, kt�ry mosna wykorzysta� w dalszych operacjach.
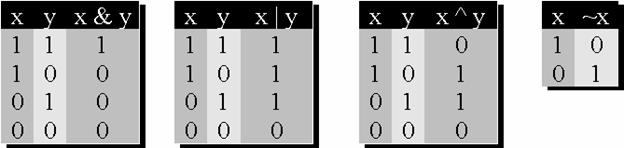
Operatory przypisania
Wszystkie operatory przypisania zwracaj� warto��, kt�ra zosta�a przypisana do danej zmiennej (lwartosci). Ponadto operatory przypisania s� prawostronnie ��czne tzn. wykonuj� si� one od prawej do lewej. Mosliwe s� wi�c zapisy:
int a, b, c;
a = b = c = 5;
Przypisanie e1 op= e2 jest r�wnowasne zapisowi: e1 = e1 op e2. Gdzie op oznacza operator.
Przyk�ad:
a += 5; oznacza a = a + 5;
Operator przecinkowy
Operator przecinkowy jest lewostronnie ��czny tzn. wyrasenia oblicza si� od lewej do prawej z tym, se wyniki oblicze� wszystkich wyrase� z wyj�tkiem ostatniego gin�. Warto�ci� operatora przecinkowego jest warto�� ostatniego wyrasenia.
Operatora przecinkowego usywa si� cz�sto do inicjacji p�tli for:
int i, j, k;
for
(i = 0, j = 5, k = 6; i < 10 && j > 0; i++)
Konwersje typ�w
W j�zyku C mamy do czynienia z r�snymi typami danych. Przypisanie danej jednego typu do danej innego typu wymaga zmiany sposobu zapisu jej warto�ci, czyli dokonania konwersji. Niekt�re konwersje s� wykonywane automatycznie, a inne wymagaj� jawnego s�dania zmiany typu.
Typy char, short int, typ wyliczeniowy, pole bitowe niezalesnie czy s� ze znakiem, czy bez mog� by� usyte wsz�dze tam, gdzie mose by� usyty typ ca�kowity. Je�li warto�� typu int jest w stanie reprezentowa� wszystkie warto�ci typu oryginalnego to jest on zamieniany na typ int. W przeciwnym wypadku jest zamieniany na typ unsigned int. Te regu�y obowi�zuj� w j�zyku ANSI C. Wiele kompilator�w C Kernighan'a i Ritchie'ego wykonywa�o konwersj� z zachowaniem znaku, czyli nigdy nie zamienia�y warto�ci bez znaku na warto�� ze znakiem. Przyk�adowy fragment programu, kt�ry mose wprowadzi� niejednoznaczno��, je�li sizeof(int) < sizeof(short):
void f(int i, unsigned short us)
Je�li teraz funkcj� f wywo�amy w nast�puj�cy spos�b: f(-1, 2)
To kompilator ANSI C zamieni us na typ int, natomiast kompilator klasycznego C zamieni najpierw i na typ unsigned int (warto�� r�wna najwi�kszej liczbie ca�kowitej), a potem us na unsigned int.
Kolejno�� wykonywania konwersji jawnych jest r�wnies nieokre�lona. Wykonanie fragmentu programu:
mose spowodowa�, se warto�� x b�dzie r�wna 255 lub -1 w zalesno�ci, czy najpierw zostanie wykonana konwersja do typu signed char a potem do int, czy najpierw do typu unsigned int a potem do int.
Liczby ca�kowite ze znakiem s� konwertowane w taki spos�b, se nie zmienia si� ich zapis bitowy. W przypadku jawnej konwersji typu bez znaku do typu ze znakiem warto�� nie zmienia si�, je�li mose by� reprezentowana przez nowy typ, w przeciwnym wypadku wynik konwersji jest zalesny od implementacji.
Konwersje z typ�w zmiennoprzecinkowych o mniejszej precyzji do typ�w o wi�kszej precyzji powoduj�, se warto�� nie ulega zmianie. Konwersje z typ�w o wi�kszej precyzji do typ�w o mniejszej precyzji powoduj�, se warto�� przyjmuje najblissz� warto�ci konwertowanej mosliw� do zapisania w nowym typie. Jesli warto�� jest spoza zakresu to wynik konwersji jest nieokre�lony.
Konwersja warto�ci typu zmiennoprzecinkowego do typu ca�kowitego powoduje zawsze obci�cie cz�ci u�amkowej. Pewne konwersje tego typu s� jednak zalesne od maszyny - cz�� u�amkowa liczby zmiennoprzecinkowej ujemnej mose by� obci�ta w jedn� lub drug� stron�. Rezultat konwersji jest nieokre�lony je�li warto�� konwertowana jest spoza zakresu nowego typu. Konwersje z typ�w ca�kowitych do zmiennoprzecinkowych s� matematycznie poprawne. Mose jednak wyst�pi� zmniejszenie dok�adno�ci, je�li dana liczba ca�kowita nie mose by� reprezentowana dok�adnie jako liczba zmiennoprzecinkowa.
Podczas obliczania wyrase� wykonywane s� w spos�b automatyczny konwersje zgodnie z zasadami opisanymi wysej.
Kolejno�� konwersji przy obliczaniu wyrase� jest nast�puj�ca:
Je�li jeden z operand�w jest typu long double, to drugi jest konwertowany do typu long double
W przeciwnym wypadku, je�li jeden z operand�w jest double, to drugi jest konwertowany do double
W przeciwnym wypadku, je�li jeden z operand�w jest float, to drugi jest konwertowany do float
W przeciwnym wypadku nast�puje promocja do typu int opisana w punkcie 1.
Nast�pnie je�li jeden operand jest typu unsigned long, to drugi jest konwertowany do typu unsigned long
W przeciwnym wypadku jesli jeden operand jest typu long int a drugi unsigned int, to je�li long int mose reprezentowa� wszystkie warto�ci typu unsigned int to unsigned int jest konwertowany do long int, w przeciwnym wypadku oba s� konwertowane do unsigned long int.
W przeciwnym wypadku je�li jeden operand jest typu long, to drugi jest konwertowany do long
W przeciwnym wypadku, je�li jeden operand jet typu unsigned, to drugi jest konwertowany do unsigned
W przeciwnym wypadku oba operandy s� typu int.
Konwersje wska�nik�w
Ponissze konwersje mog� zosta� wykonane wsz�dzie tam, gdzie wska�niki s� przypisywane, inicjalizowane, por�wnywane lub usywane w inny spos�b:
Sta�e wyrasenie, kt�rego warto�� wynosi zero jest konwertowane do wska�nika nazywanego wska�nikiem pustym (null pointer). Jest gwarantowane, se jest to wska�nik, kt�rego warto�� jest r�sna od jakiegokolwiek wska�nika wskazuj�cego na pewien obiekt. Sam wska�nik pusty mose by� pami�tany w postaci warto�ci, kt�rej reprezentacja bitowa nie jest r�wna reprezentacji bitowej liczby ca�kowitej int o warto�ci 0.
Kasdy wska�nik wskazuj�cy na typ, kt�ry nie jest modyfikowany przy usyciu const lub volatile mose zosta� skonwertowany do typu void *. W ANSI C typ void * mose by� niejawnie t�umaczony do typu T *, gdzie T jest dowolnym typem. C++ wymaga w tym przypadku jawnej konwersji.
Wska�nik do funkcji mose zosta� skonwertowany do typu void * o ile void * ma wystarczaj�c� ilo�� bit�w do przechowania tego wska�nika.
Wyrasenie typu 'array of T' mose by� skonwertowane do wska�nika na pierwszy element tej tablicy
Wyrasenie typu 'funkcja zwracaj�ca T' jest konwertowane do 'wska�nik do funkcji zwracaj�cej T' z wyj�tkiem, gdy usyty jest operator nadania adresu & lub wywo�ania funkcji ().
Preprocesor
Przed kompilacj� tekst programu poddawany jest preprocessingowi. W wyniku dzia�ania preprocesora otrzymuje si� zmodyfikowany tekst programu, kt�ry stanowi wej�cie dla kompilatora. Polecenia preprocesora s� nazywane dyrektywami.
Wiersze programu rozpoczynaj�ce si� znakiem '#' oznaczaj� dyrektywy preprocesora. Sk�adnia dyrektyw preprocesora jest niezalesna od sk�adni reszty j�zyka. Wiersze zawieraj�ce dyrektyw� preprocesora mog� wyst�pi� w dowolnym miejscu w programie.
Konwersje wykonywane przez preprocesor
Opr�cz wspomnianych wcze�niej dyrektyw, preprocesor dokonuje pewnych standardowych konwersji tekstu programu:
wszystkie wyst�pienia znak�w '' (lewy uko�nik, backslash) i bezpo�rednio po nim nowej linii s� usuwane - tzn. nast�pny wiersz jest ��czony z tym, w kt�rym znajdowa� si� znak ''.
dzieli tekst programu na symbole leksykalne i spacje. Usuwa wszystkie komentarze - komentarz jest zamieniany na pojedyncz� spacj�.

Zast�puje sekwencje specjalne w sta�ych znakowych i tekstowych ich r�wnowasnikami (np. zamienia znaki 'n' - na znak o kodzie ASCII 13)
��czy s�siednie sta�e tekstowe w jedn� sta�� tekstow� (tzn. napisy 'Ala ' 'ma kota' po preprocessingu zostan� po��czone w jeden napis: 'Ala ma kota').
Dyrektywy preprocesora
1. Makrodefinicje - #define
Do tworzenia makrodefinicji s�usy dyrektywa #define.
Sk�adnia:

Instrukcja w pierwszej postaci zleca preprocesorowi zast�powanie dalszych wyst�pie� identyfikatora wskazanym ci�giem symboli. Spacje otaczaj�ce ci�g symboli s� usuwane.
Przyk�ad:
#define BOK 8
char txt[BOK][BOK];
Deklaracja tablicy txt zostanie zamieniona w nast�puj�cy spos�b:
char txt[8][8];
Druga posta� dyrektywy #define s�usy do definicji tzw. makra funkcyjnego. W tej dyrektywie pomi�dzy identyfikatorem i nawiasem otwieraj�cym '(' nie mose by� spacji.
Dalsze wyst�pienie pierwszego identyfikatora, po kt�rym nast�puje nawias oraz ci�gi symboli oddzielone przecinkami i zako�czone nawiasem zamykaj�cym s� makrowywo�aniami. Makrowywo�anie zast�puje si� ci�giem symboli podanym w makrodefinicji. Spacje otaczaj�ce ci�g symboli s� usuwane. W podanym ci�gu kasde wyst�pienie identyfikatora z listy parametr�w formalnych makrodefinicji (umieszczonego w nawiasach) zast�puje si� symbolami reprezentuj�cymi odpowiadaj�cy mu argument aktualny makrowywo�ania. Liczba parametr�w w makrodefinicji musi by� taka sama jak liczba argument�w w makrowywo�aniu.
Przyk�ad:
#define min(x, y) (((x) < (y)) ? (x) : (y))
a = min(i, j);
Ostatnie przypisanie zostanie zast�pione przez:
a = (((i) < (j)) ? (i) : (j);
Przy definiowaniu makrodefinicji funkcyjnych nalesy wszystkie argumenty ujmowa� w nawiasy - makrodefinicje s� rozwijane tekstowo przed kompilacj�, co mose spowodowa� nieoczekiwan� zmian� znaczenia pewnych zapis�w:
#define sqr(x) x*x
res = sqr(a+4);
Przypisanie zostanie rozwini�te do:
res = a+4*a+4;
pomimo tego, se oczekujemy:
res = (a+4)*(a+4);
Przyj�o si�, se identyfikatory w makrodefinicjach s� pisane dusymi literami.
Po rozwini�ciu makrowywo�ania preprocesor przegl�da powsta�y w ten spos�b tekst w poszukiwaniu kolejnych identyfikator�w do rozwini�cia. Nie s� jednak mosliwe rozwini�cia rekursywne. Nie jest r�wnies mosliwe potraktowanie rozwini�tego tekstu jako nowej dyrektywy preprocesora.
2. Dyrektywa #undef
Dyrektywa #undef s�usy do uniewasniania poprzedniej definicji makra. Sk�adnia:

3. W��czanie plik�w - dyrektywa #include
Dyrektywa #include ma jedn� z dw�ch postaci:

Dyrektywa #include s�usy do w��czania pliku o podanej nazwie do tekstu sr�d�owego poddawanego kompilacji. W pierwszej postaci plik o podanej nazwie jest poszukiwany w katalogach zalesnych od kompilatora. W drugiej postaci plik jest najpierw poszukiwany w katalogu aktualnym i by� mose innych zdefiniowanych katalogach. Je�li tam nie zostanie znaleziony to poszukiwanie jest kontynuowane tak samo jak w przypadku pierwszej postaci, czyli w katalogach systemowych kompilatora.
4. Kompilacja warunkowa
Do kompilacji warunkowej usywa si� nast�puj�cych dyrektyw:

Dyrektywy #elif i #else s� opcjonalne.
W dyrektywach #if i #elif musz� wyst�powa� wyrasenia sta�e (tzn. takie, kt�rych warto�� mosna obliczy� podczas kompilacji). Operatory, kt�re mosna stosowa� w tych wyraseniach s� takie same, jak operatory j�zyka C; nie mosna jednak stosowa� operatora sizeof. Wewn�trz wyrasenia mosna stosowa� dodatkowy jednoargumentowy operator preprocesora:

Warto�� zwracana przez operator jest r�wna 1 je�li nazwa jest zdefiniowana lub 0 je�li nie jest zdefiniowana.
Mosna r�wnies stosowa� dyrektywy:

5. Sterowanie numerowaniem wierszy
Do zmiany numer�w linii i nazw plik�w podczas wy�wietlania komunikat�w o b��dach i ostrzeseniach s�usy dyrektywa #line.
Sk�adnia:

Nazwa pliku uj�ta w cudzys�owy jest opcjonalna. Dyrektywa #line powoduje, se kompilator przyjmie podan� liczb� jako numer nast�pnej linii i od tej liczby b�dzie numerowa� kolejne linie w pliku. Je�li nazwa pliku jest podana, to r�wnies ona zostanie zmieniona (zmiana nast�puje na potrzeby kompilacji - nie powoduje to zmiany nazw plik�w na dysku).
Dyrektywa #line ma wp�yw na predefiniowane makra __LINE__ i __FILE__.
6. Predefiniowane makra
Pewne makra s� zdefiniowane przez kompilator i mog� by� usywane podczas kompilacji:

Opr�cz podanych wysej predefiniowanych makr wyst�puj�cych w kasdym kompilatorze, niekt�re kompilatory mog� predefiniowa� swoje w�asne specyficzne makra. Ich spis oraz znaczenie jest opisane w dokumentacji takiego kompilatora.
Tworzenie program�w sk�adaj�cych si� z wielu plik�w
Program w j�zyku C mose by� zorganizowany na kilka r�snych sposob�w. Przy niewielkich programach ca�o�� tekstu mosna umie�ci� w jednym pliku. Programy bardziej rozbudowane lepiej jest podzieli� na kilka plik�w. Funkcje dotycz�ce tego samego problemu grupuje si� wtedy nacz�ciej w jednym zbiorze tekstowym.
W przypadku, gdy program jest podzielony na modu�y pojawia si� problem zapewnienia wszystkim modu�om dost�pu do tych samych definicji typ�w usytkownika, makr, prototyp�w funkcji i zapowiedzi zmiennych (extern). Problem ten rozwi�zuje si� na dwa sposoby:
tworzy si� jeden plik nag��wkowy (*.h), w kt�rym umieszcza si� wszystkie podane wcze�niej definicje i deklaracje. Kasdy z modu��w programu do��cza ten plik na pocz�tku korzystaj�c z dyrektywy preprocesora #include.
dla kasdego modu�u tworzy si� jego w�asny plik nag��wkowy zawieraj�cy definicje i deklaracje obiekt�w zdefiniowanych w tym pliku, kt�re maj� by� widoczne w innych modu�ach. Kasdy z modu��w, na pocz�tku, do��cza sw�j w�asny plik nag��wkowy oraz pliki nag��wkowe wszystkich tych modu��w, do kt�rych si� odwo�uje.
Spos�b pierwszy stosowany jest przy projektach �redniej wielkosci, spos�b drugi - przy dusych programach oraz przy tworzeniu bibliotek.
Do tworzenia program�w sk�adaj�cych si� z wielu plik�w (cz�sto nazywanych projektami) mosna usy� standardowego programu systemu UNIX - make. Program make sprawdza, kt�re pliki zosta�y zmienione od czasu ostatniej kompilacji i kompiluje tylko te pliki. W przypadku dusych projekt�w, kt�rych kompilacja w ca�o�ci mose trwa� kilkana�cie godzin, daje to znaczne skr�cenie czasu potrzebnego na wykonanie translacji. W przypadku ma�ych projekt�w mosna usy� procedury shellowej, kt�ra wykona kompilacj�. Po skompilowaniu plik�w �r�d�owych program jest ��czony w jedn� ca�o�� (do��czane s� r�wnies biblioteki) za pomoc� programu ��cz�cego (linkera).
Przyk�adowy program podzielony na pliki wg pierwszego sposobu. Strza�ki pokazuj�, kt�ry plik nag��wkowy jest do��czany do odpowiedniego pliku zawieraj�cego w�a�ciwy tekst programu.

Procedura shellowa, kt�rej zadaniem b�dzie kompilacja takiego projektu mose by� napisana w nast�puj�cy spos�b:
cc -c program1.c
cc -c program2.c
cc -c program3.c
cc -o program program1.o program2.o program3.o
Wad� przedstawionego skryptu jest to, se nie sprawdza on b��d�w, kt�re mog�y wyst�pi� podczas kompilacji, co powoduje, se trzeba czeka� as zako�czy si� ca�a kompilacja, pomimo wyst�pienia b��d�w jus w pierwszym pliku
Przyk�adowy program podzielony na pliki wed�ug sposobu drugiego
B��d! Nie zdefiniowano zak�adki.B��d! Nie zdefiniowano zak�adki.
Skrypt uwzgl�dniaj�cy mosliwo�� wyst�pienia b��d�w:
cc -c program1.c || exit 1
cc -c program2.c || exit 1
cc -c program3.c || exit 1
cc -o program program1.o program2.o program3.o
Funkcja main
Program w j�zyku 'C' rozpoczyna si� od funkcji main. Przed wywo�aniem funkcji main nast�puje jedynie inicjalizacja zmiennych globalnych i statycznych

Funkcja main mose nie zwraca� warto�ci lub zwraca� warto�� typu int. Warto�� zwracana przez funkcj� main jest kodem zako�czenia procesu przekazywanym systemowi operacyjnemu. Je�li funkcja main nie zwraca warto�ci to do systemu przekazywana jest warto�� nieokre�lona (tzn. losowa lub pewna okre�lona przez kompilator). Wykonuj�cy si� program mose zosta� r�wnies zako�czony przez wywo�anie funkcji systemowej exit(int), kt�rej jako parametr podaje si� kod zako�czenia, kt�ry ma zosta� przekazany systemowi.
Funkcja main mose posiada� nast�puj�ce parametry:
argc - liczba wska�nik�w na tekst znajduj�cych si� w drugim parametrze (tablicy argv);
argv - tablica wska�nik�w na tekst, z kt�rych kasdy jest jednym parametrem przekazanym do programu w momencie jego uruchamiania. Kasdy tekst jest zako�czony znakiem '0';
envp - tablica wska�nik�w na tekst, z kt�rych kasdy odpowiada jednej zmiennej �rodowiskowej. Kasdy z tekst�w ma posta�:
zmienna=warto��
i jest zako�czony znakiem '0'. Ostatni element tablicy envp ma warto�� NULL.
Kasdy uruchamiany program posiada przynajmniej jeden argument tzn. argc jest nie mniejsze nis 1. Tym argumentem jest nazwa pliku, w kt�rym znajduje si� kod uruchomionego programu. Niezalesnie od liczby argument�w argv[0] zawsze zawiera nazw� pliku z kodem wykonywanego programu. Kolejne argumenty znajduj� si� w nast�pnych elementach tablicy argv.
Przyk�adowy program wypisuj�cy swoj� nazw� i argumenty:
#include <stdio.h>
int
main(int argc, char *argv[])
Czas istnienia i zasi�g widoczno�ci obiekt�w
Zmienne globalne i lokalne
Kasdemu procesowi uruchamianemu pod kontrol� dowolnego systemu operacyjnego przydzielany jest fragment pami�ci dost�pnej w systemie. Pami�� zajmowan� przez proces (wykonuj�cy si� program) mosna podzieli� na kilka fragment�w:
pami�� kodu programu (instrukcji, z kt�rych sk�ada si� program)
pami�� danych programu - zmiennych globalnych i klasy static
pami�� stosu: przeznaczona do przechowywania zmiennych lokalnych, adres�w powrotu z funkcji oraz warto�ci pomocniczych.
Zmienne lokalne deklarowane s� w obr�bie bloku (instrukcji z�osonej). Do zmiennych tego rodzaju mosna odwo�ywa� si� tylko w obr�bie bloku, wewn�trz kt�rego zosta�y one zadeklarowane. Zmienne lokalne mog� by� deklarowane w trzech klasach pami�ci: auto, static i register. Klas� pami�ci zmiennej okre�la si� poprzedzaj�c jej deklaracj� s�owem kluczowym auto, static lub register. Je�li klasa zmiennej nie jest podana, to kompilator domy�lnie przyjmuje auto.
Przyk�ad:
void fun(void)
Powysszy przyk�ad pokazuje deklaracj� zmiennych i oraz k klasy auto, zmiennej j klasy register oraz statycznej zmiennej r.
Zmienne klasy auto s� tworzone na stosie w momencie, gdy rozpoczyna si� wykonanie bloku, w kt�rym s� one zadeklarowane. Natomiast s� usuwane ze stosu natychmiast po zako�czeniu wykonywania tego bloku. Przy ponownym wykonaniu tego bloku s� tworzone na nowo (by� mose w innym obszarze pami�ci) i na nowo kasowane po jego zako�czeniu. Ich tworzenie i kasowanie jest wi�c automatycznie realizowane przez program - st�d nazwa: zmienne automatyczne. Wasn� konsekwencj� opisanego zachowania jest to, se zmienne automatyczne nie zachowuj� warto�ci mi�dzy kolejnymi wykonaniami bloku. Dlatego nie mosna ich usywa� do przechowywania informacji, kt�ra ma by� wykorzystana przy nast�pnym wykonaniu bloku.
Zmienne klasy register zachowuj� si� identycznie jak zmienne automatyczne, lecz w miar� mosliwo�ci s� trzymane w rejestrach procesora lub szybkiej pami�ci, w kt�r� procesor mose by� wyposasony, a nie na stosie. St�d nazwa zmiennych tego typu: zmienne rejestrowe. Podanie s�owa register przed deklaracj� zmiennej m�wi kompilatorowi, se zmienna ta b�dzie cz�sto usywana i w zwi�zku z tym powinien umie�ci� j� w pami�ci o jak najszybszym dost�pie, co spowoduje, se program b�dzie wykonywa� si� szybciej. Zmienna rejestrowa mose by� (ale nie musi) umieszczona w rejestrze procesora, pami�ci podr�cznej lub innej pami�ci o szybkim dost�pie. Konsekwencj� takiego po�osenia zmiennej jest to, se zmienna rejestrowa nie posiada adresu, tzn. nie mosna dla zmiennej rejestrowej usy� operatora nadania adresu &.
Zmienne klasy static przechowywane s� w obszarze danych programu. S� tworzone w momencie uruchamiania programu i kasowane w momencie jego zako�czone. W zwi�zku z tym zmienne te nie zmieniaj� warto�ci mi�dzy kolejnymi wykonaniami bloku, w kt�rym zosta�y zadeklarowane. Warto�� tych zmiennej jest wi�c w pewnym sensie statyczna (zmienia si� tylko na nasze s�danie) st�d nazwa: zmienne statyczne.
Zmienne globalne deklarowane s� poza jakimkolwiek blokiem (na poziomie g��wnym) i mog� by� usyte w kasdym miejscu w programie. Zmienne globalne podobnie jak zmienne statyczne tworzone s� w obszarze danych programu w momencie jego uruchmomienia i kasowane w momencie zako�czenia.

Zmienne i funkcje klasy extern i static
Klasy pami�ci auto i register mog� by� usyte tylko do zmiennych lokalnych. Klasa static dotyczy r�wnies obiekt�w (zmiennych i funkcji) deklarowanych poza jakimkolwiek blokiem.
Obiekt zadeklarowany poza jakimkolwiek blokiem jest obiektem globalnym. Jest on widoczny od miejsca zadeklarowania do ko�ca pliku. Mose by� r�wnies widoczny w innych plikach, je�li istniej� odpowiednie predefinicje lub prototypy (dla funkcji). Je�li mamy do czynienia ze zmienn�, to b�dzie ona widoczna w innym pliku, gdy poinformujemy kompilator, se taka zmienna jest zadeklarowana w innym miejscu. S�usy do tego deklaracja zmiennej klasy extern. Taka deklaracja nie rezerwuje pami�ci na zmienn� - informuje tylko, se zmienna b�dzie zdefiniowana w dalszej cz�ci tekstu programu lub w innym pliku. Taka zmienna mose by� okre�lona mianem zewn�trznej (external).
Przyk�ad:
extern int cc;
int cc;
Je�li zmienna zadeklarowana jako extern nie b�dzie mia�a odpowiedniej deklaracji, bez modyfikatora extern, to program zostanie skompilowany poprawnie, nie zostanie jednak po��czony przez linker - wyst�pi� bowiem obiekty, kt�re nie zostan� znalezione. Podobnie, je�li wyst�pi predefinicja funkcji, a nigdzie w programie nie b�dzie kompletnej definicji tej funkcji, to program ��cz�cy zg�osi b��dy. Rzeczywista deklaracja zmiennej mose wyst�pi�, w dowolnym miejscu po deklaracji extern lub bez niej. Najcz�ciej deklaracje extern wpisuje si� w plikach nag��wkowych wraz z predefinicjami funkcji, natomiast sam� zmienn� deklaruje si� w jednym z plik�w programowych.
Klasa static dla obiekt�w globalnych jest przeciwie�stwem klasy extern - informuje bowiem kompilator, se dana zmienna lub funkcja ma by� widoczna tylko w pliku programowym, w kt�rym zosta�a zdefiniowana lub zadeklarowana. Funkcji i zmiennych globalnych klasy static usywa si� podczas tworzenia bibliotek. Pozwalaj� one bowiem na to, by usytkownik tej biblioteki widzia� tylko te funkcje i zmienne, kt�re s� mu potrzebne. Do innych funkcji lub zmiennych zwi�zanych z realizacj� zada� wykonywanych przez bibliotek� nie ma dost�pu (nie mose wtedy spowodowa� szk�d zwi�zanych z niew�a�ciwym usyciem funkcji lub przypisaniem b��dnej warto�ci pewnej zmiennej globalnej).
Zmienne z modyfikatorami const i volatile
Kasda zmienna mose posiada� modyfikator const lub volatile.

Zmienna z modyfikatorem const mose zosta� zainicjowana w momencie utworzenia (za pomoc� operatora przypisania w deklaracji lub w momencie wywo�ania funkcji, je�li jest ona parametrem tej funkcji). Zmienna z modyfikatorem const mose by� umieszczona przez kompilator w pami�ci tylko do odczytu, w zwi�zku z czym zapis do takiej zmiennej mose spowodowa� nieprzewidziane skutki.

Dzia�anie modyfikatora volatile jest zalesne od implementacji.
Przyk�ady:
int strlen(const char *s) /* s nie b�dzie zmieniane */
volatile cos;
Zasi�g identyfikator�w

Je�li w obszarze widoczno�ci pewnej zmiennej zostanie zadeklarowana inna zmienna o tej samej nazwie, to nowa zmienna staje si� dost�pna, natomiast zmienna pierwotna przestaje by� widoczna (zostaje zas�oni�ta). Zmienna pierwotna zaczyna by� widoczna ponownie, gdy ko�czy si� zakres zmiennej zas�aniaj�cej. Jest to tzw. regu�a przes�aniania.
Przyk�ad:
void main(void)
printf('Liczba
3: %dn', i++);
Wykonanie powysszego programu spowoduje wypisanie:
Liczba 1: 5;
Liczba
2: 8;
Liczba
3: 6;
Zmienna i w funkcji main zosta�a bowiem zas�oni�ta przez zmienn� i zadeklarowan� w bloku. W momencie zas�oni�cia wszystkie odwo�ania dotycz� zmiennej zas�aniaj�cej - zmienna zas�oni�ta nie jest dost�pna.
Standardowe funkcje j�zyka C
Funkcje Wej�cia/Wyj�cia
Funkcja printf
Funkcja printf s�usy do zapisywania w standardowym strumieniu wyj�ciowym r�snych danych.
Sk�adnia:

Opis:
Funkcja printf analizuje najpierw przekazany jako pierwszy argument tekst, a nast�pnie na podstawie informacji zawartych w tym tek�cie, wypisuje kolejne warto�ci. Ilo�� warto�ci musi by� taka jak wynika z przekazanego formatu. W szczeg�lnym przypadku do funkcji printf mose zosta� przekazany tylko format. Tekst przekazywany jako format, sk�ada si� z tekstu, kt�ry zostanie wypisany tak jak zosta� przekazany oraz informacji o koniecznych konwersjach. Informacja o konwersji rozpoczyna si� znakiem '%'. Kasda taka informacja odpowiada jednej warto�ci przekazanej jako kolejny argument. W wypisywanym tek�cie, kolejne warto�ci pojawiaj� si� w miejscu odpowiednich konwersji '%'. Same znaki '%' nie s� wypisywane. W przypadku, gdy chcemy wypisa� na ekranie znak '%' w podanym tek�cie nalesy wpisa� '%%'.
Przyk�ady:
printf('Dzisiaj jest
wtorek!n'); /* Dzisiaj jest wtorek */
printf('120
%% 10 = 0n'); /* 120 % 10 = 0 */
Kasda konwersja sk�ada si� z:
Znaku '%'
Zera lub wi�cej opcji:
- wyr�wnanie do lewej wewn�trz pola b�d�cego rezultatem konwersji
+ rozpocz�cie wyniku znakiem (+ lub -)
Opcjonalnego ci�gu liczb, kt�ry specyfikuje minimaln� szeroko�� pola. Je�li konwertowana warto�� ma mniej liter nis szeroko�� pola, to jest uzupe�niana spacjami z lewej strony, chyba se opcja wyr�wnywania do lewej jest wyspecyfikowana - wtedy warto�� jest uzupe�niana spacjami z prawej strony.
Opcjonalnego parametru okre�laj�cego precyzj�. Parametr precyzji sk�ada si� z '.' (znaku kropki) i bezpo�rednio po niej nast�puj�cego ci�gu cyfr. Je�li precyzja nie jest podana, to przyjmuje si� 0. Parametr precyzji okre�la:
minimaln� liczb� cyfr jakie maj� zosta� wypisane dla konwersji d, u, o, x, X
liczb� cyfr jakie maj� si� pojawi� po kropce dziesi�tnej dla konwersji e lub f
maksymaln� liczb� znacz�cych cyfr dla konwersji g
maksymaln� liczb� wypisywanych znak�w dla konwersji s
Opcjonalnej litery 'l' lub 'h' oznaczaj�cych odpowiednio, se dana konwersja (d, u, o, x, X) dotyczy danej z modyfikatorem odpowiednio long lub short.
Litery oznaczaj�cej jaka konwersja ma zosta� wykonana.
d akceptuje parametr typu ca�kowitego i wykonuje konwersj� do zapisu ca�kowitego ze znakiem
u akceptuje parametr typu ca�kowitego (ca�kowitego bez znaku) i wypisuje go jako liczb� ca�kowit� bez znaku.
o akceptuje parametr typu ca�kowitego i wypisuje go w postaci liczby ca�kowitej bez znaku w systemie �semkowym.
X akceptuje parametr typu ca�kowitego i wypisuje go w postaci liczby ca�kowitej bez znaku w systemie szesnastkowym. W miejsc cyfr z zakresu 11 - 15 s� wstawiane znaki 'abcdef' dla konwersji x lub znaki 'ABCDEF' dla konwersji X.
f akceptuje warto�� typu float lub double i konwertuje j� do postaci: [-]ddd.ddd. Liczba cyfr po kropce dziesi�tnej odpowiada podanej w specyfikacji precyzji. Je�li precyzja nie jest wyspecyfikowana, wypisywane jest 6 cyfr. Je�li precyzja jest r�wna 0, to kropka dziesi�tna nie jest wypisywana.
E akceptuje warto�� typu float lub double i konwertuje j� do postaci liczby zmiennoprzecinkowej ze specyfikacj� wyk�adnika:
[-]d.ddde+|-dd. Przed kropk� dziesi�tn� pojawia si� zawsze jedna cyfra. Ilo�� cyfr po kropce dziesi�tnej odpowiada podanej w specyfikacji precyzji. Je�li precyzja nie jest wyspecyfikowana, wypisywane jest 6 cyfr. Je�li precyzja jest r�wna 0, to kropka dziesi�tna nie jest wypisywana. Dla konwersji E wypisywana jest litera 'E' oznaczaj�ca wyk�adnik zamiast litery 'e'
G akceptuje warto�� typu float lub double i wypisuje w postaci takiej jak konwersje e, E lub f z precyzj� okre�laj�c� ilo�� cyfr znacz�cych. Kropka dziesi�tna pojawia si� tylko wtedy, gdy znajduje si� za ni� jaka� cyfra. Rodzaj konwersji zalesy od wypisywanej warto�ci. Konwersja e (E je�li podano G) jest usywana tylko wtedy, gdy wyk�adnik pot�gi jest mniejszy od -4 albo wi�kszy lub r�wny precyzji.
c akceptuje i wypisuje pojedynczy znak.
s akceptuje warto�� b�d�c� stringiem (char *). Znaki podane stringu s� wypisywane as do napotkania znaku o kodzie 0 lub wypisania liczby znak�w okre�lonych przy specyfikacji precyzji.
p akceptuje wska�nik (void *) i wypisuje go w postaci szesnastkowej.
Warto�� zwracana:
Je�li wywo�anie zko�czy�o si� sukcesem, funkcja zwraca liczb� wy�wietlonych znak�w.
Przyk�ady:
printf('xx%10syyn', 'Ala');
/* xx Alayy */
printf('xx%-10syyn',
'Ala'); /* xxAla yy */
printf('%d+%d
= %dn', 2, 3, 2+3); /* 2+3 = 5 */
Funkcja scanf
Funkcja scanf odczytuje dane ze standardowego strumienia wej�ciowego, wykonuje ich konwersj� w zalesno�ci od podanego formatu i zachowuje rezultat w podanym miejscu w pami�ci.
Sk�adnia:

Opis:
Funkcja scanf analizuje najpierw przekazany jako pierwszy argument tekst, a nast�pnie na podstawie informacji zawartych w tym tek�cie, odczytuje ze standardowego strumienia wej�ciowego kolejne warto�ci. Ilo�� warto�ci musi by� taka jak wynika z przekazanego formatu.
Tekst formatu mose zawiera� nast�puj�ce znaki:
Spacji, tabulacji, nowej linii lub wysuni�cia strony. Kasdy z tych znak�w powoduje odczyt wej�cia as do napotkania nast�pnego znaku nie b�d�cego spacj�, tabulacj�, now� lini� lub znakiem wysuni�cia strony. Ko�cowe znaki spacji, tabulacji, nowej linii i wysuni�cia strony nie s� odczytywane.
Dowolnej litery z wyj�tkiem '%', kt�ra musi odpowiada� takiej samej literze w strumieniu wej�ciowym
Konwersji rozpoczynaj�cej si� znakiem '%'
Kasda konwersja sk�ada si� z:
Znaku '%'.
Opcjonalnego znaku '*' zakazuj�cego dokonywania przypisania.
Opcjonalnej maksymalnej numerycznej szeroko�ci pola.
Opcjonalnej litery okre�laj�cej rozmiar przekazanej zmiennej:
l d�uga liczba ca�kowita ze znakiem (signed long), je�li poprzedza kody d, u, o, lub x;
L zmienna podw�jnej precyzji (double), je�li poprzedza kody e, f lub g
h kr�tka liczba ca�kowita ze znakiem (short), je�li poprzedza kody d, u, o lub x
Kodu konwersji
Ostatecznie kasda konwersja ma posta�:
%[*] [szeroko��] [rozmiar] kod_konwersji
Rezultat kasdej z konwersji jest zapisywany do odpowiedniej zmiennej, do kt�rej wska�nik zosta� przekazany w wywo�aniu funkcji scanf, chyba se w specyfikacji konwersji podano znak '*'. Znak '*' umosliwia opis pola wej�ciowego, kt�re powinno by� pomini�te. Pole wej�ciowe jest stringiem nie zawieraj�cym spacji, tabulacji, znak�w ko�ca linii i wysuni�cia strony. Ci�gnie si� ono, as do napotkania znaku nie pasuj�cego do podanego wzorca lub wyczerpania szeroko�ci, je�li szeroko�� pola zosta�a wyspecyfikowana.
Kod konwersji m�wi, w jaki spos�b nalesy interpretowa� pole wej�ciowe. Odpowiadaj�cy mu wska�nik, musi wskazywa� na zmienn� podanego typu. Nie podaje si� wska�nika dla pola z zakazem przypisania (znakiem '*').
Mosna stosowa� nast�puj�ce kody konwersji:
akceptuje znak '%' w strumieniu wej�ciowym, nie jest wykonywana sadna inna konwersja.
d akceptuje warto�� ca�kowit�; wska�nik musi wskazywa� na zmienn� ca�kowit�.
u akceptuje warto�� ca�kowit� bez znaku; wska�nik musi wskazywa� na zmienn� ca�kowit� bez znaku.
o akceptuje warto�� ca�kowit� zapisan� �semkowo; wska�nik musi wskazywa� na zmienn� ca�kowit�.
x akceptuje warto�� ca�kowit� zapisan� szesnastkowo; wska�nik musi wskazywa� na zmienn� ca�kowit�.
f, g akceptuje warto�� zmiennoprzecinkow�; wska�nik powinien wskazywa� na zmienn� typu float. Warto�� zmiennoprzecinkowa mose zawiera� znak oraz by� zapisana w postaci wyk�adniczej.
p akceptuje warto�� szesnastkow� bez znaku (warto�� wska�nika); wska�nik wskazuje na wska�nik na void.
s akceptuje string (ci�g znak�w); wska�nik musi wskazywa� na tablic� znak�w na tyle dus�, by m�c do niej wprowadzi� ten string oraz ko�cz�cy go znak '0'. Pole wej�ciowe ko�czy si� znakiem spacji, tabulacji, nowej linii lub wysuni�cia strony. Znak '0' jest dodawany automatycznie.
c akceptuje pojedynczy znak; wska�nik musi wskazywa� na zmienn� typu char. Zwyk�e pomijanie pustych znak�w jest zablokowane. Je�li jest podana szeroko�� pola, wska�nik powinien wskazywa� na tablic� znak�w i do niej zostanie wprowadzona wtedy podana liczba znak�w.
[wzorzec] akceptuje ci�g znak�w, kt�ry mose zosta� dopasowany do podanego wzorca; wska�nik musi wskazywa� na tablic� znak�w o rozmiarze wystarczaj�cym do przechowania tekstu oraz ko�cz�cego znaku '0'. Znak '0' jest dopisywany automatycznie. Wzorzec mose zawiera� znaki, kt�re maj� zosta� dopasowane. Je�li wzorzec rozpoczyna si� od znaku '^' oznacza to, se mog� by� do niego dopasowane wszystkie znaki poza podanymi we wzorcu. We wzorcu mosna podawa� zakres liter np: [0123456789] jako [0-9]. Pierwszy parametr musi by� wtedy leksykalnie mniejszy od drugiego. Mosna do wzorca do��czy� znak ']' jako pierwszy lub bezpo�rednio po znaku '^'. Nie jest on wtedy traktowany jako nawias zamykaj�cy wzorzec.
Warto�� zwracana:
Funkcja zwraca ilo�� poprawnie dopasowanych i przypisanych warto�ci. Warto�� zwracana mose by� r�wna 0, je�li saden ci�g znak�w nie zosta� dopasowany. Je�li strumie� wej�ciowy ko�czy si� przed wykryciem konfliktu lub dokonaniu konwersji, zwracana jest warto�� EOF.
Funkcje operacji na plikach
W celu operacji na plikach w j�zyku C zdefiniowane zosta�o makro o nazwie FILE (jego definicja znajduje si� w pliku <stdio.h>). Funkcje s�us�ce do operacji na plikach dzia�aj� na wska�nikach do FILE (FILE *).

Funkcja fopen
Sk�adnia:

Opis:
Funkcja fopen otwiera plik i zwraca wska�nik do niego. Parametr �cieska okre�la �ciesk� do pliku (lub tylko nazw�, je�li plik ma zosta� otwarty w katalogu aktualnym). Plik mosna otworzy� w trybie do odczytu, zapisu, dopisywania i modyfikacji. Dwie pierwsze mosliwo�ci s� standardowe dla typowego pliku sekwencyjnego. Otwarcie w trybie dopisywania umosliwia dodawanie danych na ko�cu pliku. Najwi�ksze mosliwo�ci daje otwarcie w trybie modyfikacji (niestety nie jest dost�pne dla wszystkich rodzaj�w urz�dze�). W trybie modyfikacji mosna dokonywa� zapisu i odczytu. Zmiana rodzaju operacji (z zapisu na odczyt lub z odczytu na zapis) musi by� poprzedzona wywo�aniem jednej z funkcji: fflush, fseek, fsetpos lub rewind.
Parametr typ okre�la tryb otwarcia pliku i mose by� jednym z podanych tekst�w:
r otwiera plik tekstowy do odczytu;
w tworzy nowy tekstowy plik lub kasuje poprzedni i otwiera go w trybie do zapisu;
a otwiera plik tekstowy w trybie dopisywania lub tworzy nowy plik, je�li plik o podanej nazwie nie istnieje;
rb otwiera plik binarny w trybie do odczytu;
wb tworzy lub kasuje plik binarny i otwiera w trybie do odczytu;
ab tworzy plik binarny lub otwiera plik istniej�cy w trybie dopisywania;
r+ otwiera plik w trybie modyfikacji;
w+ kasuje poprzedni� zawarto�� pliku lub tworzy nowy w trybie modyfikacji;
a+ tworzy nowy plik lub otwiera plik istniej�cy w trybie modyfikacji poza ko�cem pliku;
r+b lub rb+ otwiera plik binarny w trybie modyfikacji;
w+b lub wb+ tworzy nowy plik binarny lub kasuje poprzedni i otwiera w trybie modyfikacji;
a+b lub ab+ tworzy lub otwiera plik binarny (je�li istnieje) w trybie modyfikacji poza ko�cem pliku;
Warto�� zwracana:
Wska�nik r�sny od NULL, je�li operacja zako�czy�a si� sukcesem lub NULL w przypadku niepowodzenia.
Funkcje fprintf i fscanf
Sk�adnia:

Opis:
Dzia�anie funkcji printf odpowiada funkcji fprintf z pierwszy parametrem stdout, funkcja scanf odpowiada fscanf z pierwszym parametrem stdin. Wszystkie parametry (z wyj�tkiem pierwszego) i warto�ci zwracane s� takie same jak w funkcjach printf i scanf. Pierwszy parametr funkcji fprintf musi by� wska�nikiem do FILE otwartym w trybie do zapisu. Pierwszy parametr funkcji fscanf musi by� wska�nikiem do FILE otwartym w trybie do odczytu.
Funkcje getc, fgetc, getchar
Sk�adnia:

Opis:
Funkcje getc, fgetc i getchar s�us� do pobierania pojedynczych znak�w z otwartego pliku lub standardowego strumienia wej�ciowego. Niekt�re z nich nie s� rzeczywistymi funkcjami, ale makrami: getc i getchar.
Makro getc zwraca nast�pny bajt odczytany z podanego pliku i przesuwa znacznik pliku na bajt nast�pny. Makro getc nie mose by� usyte wtedy, gdy wymagana jest funkcja - nie mosna na przyk�ad zdefiniowa� wska�nika, kt�ry by na nie wskazywa�.
Funkcja fgetc spe�nia te same zadania co makro getc, ale jest rzeczywist� funkcj�. Wywo�anie fgetc jest wolniejsze nis getc, ale zajmuje mniej miejsca.
Makro getchar zwraca nast�pny bajt z pliku stdin (standardowy strumie� wej�ciowy).
Funkcje getc, fgetc i getchar zwracaj� odczytany bajt w postaci liczby typu int albo sta�� EOF, je�li wyst�pi� b��du lub osi�gni�to koniec pliku.
Funkcje putc, fputc, putchar
Sk�adnia:

Opis:
Makrami s�: putc i putchar. Makro putc zapisuje liter� c do pliku wskazywanego przez stream w miejscu aktualnego wska�nika tego pliku. Makro putchar robi to samo, z t� r�snic�, se wynik zapisuje do pliku stdout (standardowy strumie� wyj�ciowy).
Funkcja fputc pracuje dok�adnie tak samo jak putc, ale nie jest makrem. W zwi�zku z tym jej wywo�anie jest wolniejsze, ale zajmuje mniej miejsca.
W przypadku poprawnego wykonania operacji funkcje putc, fputc i putchar zwracaj� zapisany znak. W przypadku wyst�pienia b��du zwracana jest sta�a EOF.
Funkcja fflush
Sk�adnia:

Opis:
Funkcja fflush zapisuje dane znajduj�ce si� w buforach obs�ugi podanego pliku. Plik pozostaje nadal otwarty. Funkcja fflush zwraca warto�� 0 w przypadku wywo�ania zako�czonego sukcesem lub warto�� EOF, je�li wyst�pi� b��d.
Funkcja fclose
Sk�adnia:

Opis:
Funkcja fclose zapisuje wszystkie zmiany dokonane w pliku i zamyka go. Kasdy otwarty przez program plik powinien by� zamkni�ty przez ten program.
Funkcja fclose zwraca warto�� 0, je�li operacja zako�czy�a si� powodzeniem lub EOF w przypadku wyst�pienia b��du.
Funkcja feof
Sk�adnia:

Opis:
Makro feof zwraca warto�� niezerow�, je�li wykryty zosta� koniec pliku wskazywanego przez stream.
Funkcje gets, fgets
Sk�adnia:

Opis:
Funkcja gets odczytuje dane ze standardowego strumienia wej�ciowego (stdin) i wpisuje je do tablicy wskazywanej przez string. Wczytywanie ko�czy si� w momencie napotkania ko�ca pliku lub znaku nowej linii. Je�li gets ko�czy si� z powodu napotkania znaku ko�ca linii, znak ten jest usuwany, a w jego miejsce wpisywany jest znak '0' ko�cz�cy tekst w j�zyku C. Rozmiar przekazanej tablicy nie jest kontrolowany, w zwi�zku z czym istnieje niebezpiecze�stwo zapisu do obszaru poza t� tablic�.
Funkcja fgets odczytuje z pliku wskazywanego przez stream kolejne bajty i zapisuje je do tablicy wskazywanej przez string. Odczytywanie ko�czy si� w momencie napotkania ko�ca pliku, znaku nowej linii lub wczytaniu number - 1 znak�w. Nast�pnie do tablicy string na ko�cu wprowadzonego tekstu wpisywany jest znak '0'. Funkcja fgets jest bezpieczniejsza, poniewas sprawdza rozmiar tablicy.
Funkcje gets i fgets zwracaj� wska�nik na string, je�li jakie� dane zosta�y wprowadzone i nie wyst�pi� b��d lub NULL w przypadku wyst�pienia b��du lub wtedy, gdy b��d nie wyst�pi�, ale sadne znaki do string nie zosta�y zapisane.
Funkcje puts, fputs
Sk�adnia:
 Opis:
Opis:
Funkcja puts zapisuje tekst wskazywany przez string do standardowego strumienia wyj�ciowego (stdout) i nast�pnie zapisuje r�wnies znak ko�ca linii. Tekst przekazany jako string musi by� zako�czony znakiem '0'.
Funkcja fputs zapisuje tekst wskazywany przez parametr string (musi by� zako�czony znakiem '0') do pliku wskazywanego przez stream. Funkcja fputs nie dodaje znaku ko�ca linii po zapisaniu tekstu. �adna z funkcji puts i fputs nie zapisuje ko�cz�cego tekst znaku '0'.
Obie funkcje zwracaj� liczb� zapisanych znak�w w przypadku powodzenia lub sta�� EOF je�li wyst�pi� b��d.
Funkcje fseek, rewind, ftell, fgetpos, fsetpos
Sk�adnia:

Opis:
Funkcja fseek powoduje przesuni�cie wska�nika pliku stream. Przesuni�cie offset mose dodatnie r�wne 0 lub ujemne. Spos�b przesuni�cia wska�nika pliku zalesy od parametru whence:
je�li whence jest r�wne 0, to wska�nik jest przesuwany do pozycji o numerze podanym w parametrze offset;
je�li whence jest r�wne 1, to wska�nik jest przesuwany do pozycji o numerze b�d�cym sum� aktualnej pozycji i parametru offset;
je�li whence jest 2, to wska�nik pliku jest przesuwany do pozycji b�d�cej sum� rozmiaru pliku i parametru offset.
Funkcja fseek nie mose by� usywana do pliku oznaczaj�cego terminal.
W przypadku powodzenia funkcja fseek zwraca 0, je�li wyst�pi� b��d - zwracana jest warto�� niezerowa.
Funkcja rewind(stream) jest r�wnowasna funkcji fseek(stream, 0, 0).
Funkcja ftell zwraca aktualn� pozycj� wska�nika pliku.
Funkcja fsetpos ma podobne dzia�anie do fseek, natomiast funkcja fgetpos - do ftell. Funkcje fsetpos i fgetpos zwracaj� warto�� 0 w przypadku powodzenia lub warto�� -1 je�li wyst�pi� b��d.
Funkcje fread i fwrite
Sk�adnia:

Opis:
Parametry funkcji oznaczaj�:
pointer - wska�nik na tablic�;
size - rozmiar elementu tablicy;
numberOfItems - liczba element�w do odczytania lub zapisania;
stream - plik, na kt�rym wykonywana jest operacja.
Funkcja fread kopiuje numberOfItems element�w z podanego pliku do tablicy. Kopiowanie ko�czy si� w przypadku wyst�pienia b��du, ko�ca pliku lub po skopiowaniu podanej liczby element�w. Wska�nik pliku jest przesuwany, tak by wskazywa� pierwszy nie odczytany element.
Funkcja fwrite zapisuje podan� liczb� element�w do pliku okre�lonego przez stream. Zapis ko�czy si� je�li wyst�pi� b��d lub zapisano s�dan� ilo�� danych.
Obie funkcje zwracaj� liczb� rzeczywi�cie zapisanych element�w.
Zarz�dzanie pami�ci�
Kasdy program napisany w j�zyku C ma dost�p do dw�ch obszar�w pami�ci, w kt�rych mose by� przechowywana zmienna ilo�� danych: stosu i sterty. Na stosie przechowywane s� zmienne lokalne (automatyczne). R�wnies wywo�ania funkcji zostawiaj� �lad na stosie, aby by�o wiadomo dok�d program ma powr�ci� po zako�czeniu funkcji. Stos obs�ugiwany jest automatycznie i programista nie ma mosliwo�ci ingerencji w t� obs�ug� (w zwyk�ym programie). Drugi obszar pami�ci, z kt�rego mosna korzysta� pisz�c programy w j�zyku C, to sterta. Sterta jest obszarem pami�ci udost�pnianym przez system operacyjny wszystkim wykonuj�cym si� procesom. W systemach wielodost�pnych (np. UNIX) istniej� jednak zabezpieczenia, kt�re uniemosliwiaj� dost�p procesu do pami�ci, z kt�rej korzysta inny proces (chyba, se tamten proces zezwoli na dost�p innemu procesowi). Poniewas wielko�� sterty jest ograniczona (cho� na og� do�� dusa - cz�sto znacznie wi�ksza nis obszar stosu), wi�c procesy dzia�aj�ce w systemie wsp�zawodnicz� ze sob� o dost�p do tego obszaru. Przydzia�em pami�ci zajmuje si� system operacyjny, mose on jednak przydzieli� tylko tyle pami�ci ile w danej chwili jest wolne. Dlatego procesy, kt�rym pami�� zosta�a przydzielona, powinny informowa� system, se z niej nie korzystaj� (zwalnia�) natychmiast po tym jak pami�� przestaje by� im potrzebna.
Do obs�ugi pami�ci s�us� zmienne wska�nikowe. Dusym problemem jest takie napisanie programu, by nie pr�bowa� on czyta� lub zapisywa� pami�ci, kt�ra nie zosta�a mu przydzielona (powoduje to b��d wykonania i natychmiastowe zako�czenie programu w systemach z ochron� pami�ci lub bardzo trudne do wykrycia b��dy w systemach bez ochrony pami�ci lub wtedy, gdy program modyfikuje swoj� pami��, ale w nieprzewidzianym miejscu) i r�wnocze�nie zwalnia� ca�� przydzielon� i zb�dn� jus pami��. Nalesy pami�ta�, se wska�niki, podobnie jak inne zmienne, w momencie deklaracji maj� warto�� nieokre�lon� i programista musi zadba�, by ich warto�� by�a sesnsowna.
Sta�a NULL
W pliku nag��wkowym stdio.h zdefiniowana jest sta�a o nazwie NULL. Jej warto�ci� jest 0 zrzutowane na typ wska�nikowy. Kompilator gwarantuje, se sadna funkcja s�us�ca do przydzia�u (alokacji) pami�ci, nie zwr�ci tej warto�ci, je�li pami�� zosta�a przydzielona. Oznacza to, se wska�nik, kt�rego warto�� jest r�wna NULL nie wskazuje nigdy, na saden obszar pami�ci przydzielony procesowi. Warto�� ta s�usy do informowania, se wska�nik jest pusty - na nic nie wskazuje.
Funkcje malloc i calloc
Sk�adnia:

Opis:
Funkcje malloc i calloc s�us� do przydzia�u pami�ci. Funkcja malloc przydziela podan� ilo�� bajt�w. Zawarto�� przydzielonej pami�ci jest nieokre�lona. Funkcja calloc alokuje na stercie w jednym ci�g�ym obszarze numberOfElements element�w, z kt�rych kasdy ma rozmiar elementSize (czyli przydzielane jest numberOfElements * elementSize bajt�w). Przed zwr�ceniem wska�nika funkcja calloc wype�nia zerami przydzielony obszar pami�ci. Obie funkcje zwracaj� wska�nik do zaalokowanego miejsca w pami�ci lub NULL je�li alokacja si� nie powiod�a (zbyt ma�o wolnej pami�ci).
Funkcja realloc
Sk�adnia:

Opis:
Funkcja realloc zmienia rozmiar bloku pami�ci wskazywanego przez pointer na podany w parametrze size i zwraca wska�nik do powi�kszonego obszaru. Dane, kt�re znajdowa�y si� w poprzednim obszarze pozostaj� nie zmienione. Je�li istnieje mosliwo�� powi�kszenia bloku pami�ci bez alokacji nowego - realloc, zwi�ksza ten rozmiar. Najcz�ciej jednak alokowany jest nowy obszar pami�ci i do niego s� kopiowane dane z poprzedniego. Nast�pnie niepotrzebny jus obszar jest zwalniany. Je�li obszaru nie mosna powi�kszy�, to funkcja realloc zwraca NULL, natomiast pami��, na kt�r� wskazywa� przekazany wska�nik pointer zostaje zwolniona. W przypadku pomniejszania bloku pami�ci niezmieniona zostaje ta cz�� danych, kt�ra mie�ci si� w obszarze o nowym rozmiarze.
Funkcja free
Sk�adnia:

Opis:
Funkcja free zwalnia przydzielony funkcj� malloc lub calloc obszar pami�ci. Od tej pory pointer ma warto�� niepoprawn�. Programista sam musi zadba� o to, by nada� mu warto�� NULL.
Funkcje operacji na tekstach
W j�zyku C teksty s� tablicami znakowymi (char * ). D�ugo�� tekstu nie jest nigdzie zapami�tana - zak�ada si� se tekst ko�czy si� znakiem o kodzie 0 ('0'). Je�li w tek�cie wyst�puje znak '0' w innym miejscu nis na ko�cu lub nie wyst�puje wcale, to standardowe funkcje operacji na tekstach nie b�d� dzia�a� poprawnie.
Funkcje strcat i strncat
Sk�adnia:

Opis:
Funkcja strcat do��cza na ko�cu tekstu wskazywanego przez string1 kopi� tekstu string2. Rezultat jest zako�czony znakiem '0'. Nie jest alokowana pami�� - po��czone teksty musz� si� zmie�ci�w obszarze wskazywanym przez string1.
Funkcja strncat do��cza na ko�cu tekstu string1 co najwysej podan� w trzecim parametrze liczb� znak�w z tekstu string2. Kopiowanie ko�czy si� po napotkaniu w string2 znaku '0' lub skopiowaniu podanej liczby znak�w. Obie funkcje zwracaj� wska�nik do po��czonego ci�gu znak�w (string1).
Funkcje strcmp i strncmp
Sk�adnia:

Opis:
Funkcje strcmp i strncmp s�us� do por�wnywania tekst�w. Teksty por�wnywane s� znak po znaku od lewej do prawej, as do napotkania pierwszej niezgodno�ci. Duse i ma�e litery s� rozr�sniane. Por�wnywanie odbywa si� wed�ug kod�w stosowanych na danej maszynie (ASCII). Obie funkcje zwracaj� warto�� mniejsz� od 0, je�li string1 jest mniejszy od string2, wi�ksz� od 0 je�li string1 jest wi�kszy od string2 lub r�wn� 0 je�li string1 jest r�wny string2. Funkcja strcmp por�wnuje ca�e teksty, funkcja strncmp nie wi�cej nis podan� w parametrze number ilo�� znak�w.
Funkcje strcpy i strncpy
Sk�adnia:

Opis:
Funkcje strcpy i strncpy s�us� do kopiowania ci�g�w znak�w. Funkcja strcpy kopiuje tekst przekazany w parametrze source do obszaru pami�ci wskazywanego przez destination. Kopiowanie ko�czy si� w momencie skopiowania znaku '0'. Funkcja strncpy kopiuje podan� liczb� znak�w z tekstu source do obszaru wskazywanego przez destination. Je�li tekst wskazywany przez source jest kr�tszy nis podana liczba, destination jest uzupe�niany z prawej strony znakami '0' do d�ugo�ci number. Obie funkcje zwracaj� wska�nik destination.
Funkcja strlen
Sk�adnia:

Opis:
Funkcja strlen zwraca ilo�� znak�w wchodz�cych w sk�ad przekazanego string'u. Ko�cz�cy tekst znak '0' nie jest wliczany.
Funkcja strchr, strrchr i strpbrk
Sk�adnia:

Opis:
Funkcja strchr zwraca wska�nik na pierwsze wyst�pienie litery character w tek�cie wskazywanym przez string. Ko�cz�cy string znak '0' wchodzi w sk�ad tego stringu. Je�li litera nie wyst�puje zwracany jest wska�nik NULL.
Funkcja strrchr zwraca wska�nik na ostatnie wyst�pienie litery character w stringu. Je�li litera nie wyst�puje zwracana jest warto�� NULL.
Funkcja strpbrk zwraca wska�nik na pierwsze wyst�pienie jednej z liter wchodz�cych w sk�ad string2 w tek�cie wskazywanym przez string1. Je�li w tek�cie nie ma sadnej litery z parametru string2, zwracana jest warto�� NULL.
Funkcja strspn i strcspn
Sk�adnia:

Opis:
Funkcja strspn zwraca d�ugo�� pocz�tkowej cz�ci tekstu wskazywanego przez string1, kt�ra sk�ada si� tylko z liter wchodz�cych w sk�ad string2.
Funkcja strcspn zwraca d�ugo�� pocz�tkowej cz�ci tekstu wskazywanego przez string1, kt�ra sk�ada si� z liter nie wchodz�cych w sk�ad string2.
Funkcja strstr
Sk�adnia:

Opis:
Funkcja strstr znajduje pierwsze wyst�pienie ci�gu znak�w string2 (wy��czaj�c ko�cz�cy string2 znak '0') w tek�cie string1 i zwraca wska�nik do znalezionego ci�gu znak�w (w string1). Je�li ci�g znak�w nie zosta� znaleziony zwracana jest warto�� NULL. Je�li string2 jest ci�giem pustym - zwracany jest wska�nik string1.
Funkcja strdup
Sk�adnia:

Opis:
Funkcja strdup zwraca wska�nik do nowego ci�gu znak�w, kt�ry jest kopi� przekazanego string1. Pami�� jest alokowana przy usyciu funkcji malloc. Funkcja strdup zwraca NULL je�li nie mosna zaalokowa� wymaganej pami�ci.
Struktury dynamiczne
Kasdy wi�kszy program wykorzystuje z�osone struktury tworzone na stercie, kt�re nazywane s� strukturami dynamicznymi, poniewas ich wielko�� i stopie� z�osono�ci zmienia si� w czasie dzia�ania programu. Do struktur dynamicznych zalicza si� listy, stosy, kolejki i drzewa.
Lista jednokierunkowa
Logiczn� struktur� listy jednolierunkowej przedstawia rysunek:

Kasdy element listy zawiera pewne dane oraz wska�nik na nast�pny element. Ostatni element listy jednokierunkowej ma wska�nik ustawiony na NULL. Dost�p do listy umosliwia wska�nik na jej pierwszy element (na rysunku nazwany 'pocz�tek'). Odpowiadaj�ca jednemu elementowi listy definicja struktury ma nast�puj�c� posta�:
struct ListElem
Listy jedno i dwukierunkowe s� najcz�ciej wykorzystywanymi w programach strukturami dynamicznymi. Umosliwiaj� przechowywanie dowolnej ilo�ci danych (zmiennej w czasie). Wstawianie do listy na pocz�tku, na ko�cu i w �rodku jest stosunkowo proste. Dlatego mosna �atwo zachowa� uporz�dkowanie. Wyszukiwanie w listach jest jednak ma�o efektywne - pomimo tego, se lista jest uporz�dkowana, nalesy przegl�da� wszystkie elementy po kolei, co daje z�osono�� rz�du n/2, gdzie n jest liczb� element�w. Metoda binarna przy wyszukiwaniu w tablicy uporz�dkowanej ma natomiast z�osono�� logarytmiczn�.
Lista dwukierunkowa
Kasdy element listy dwukierunkowej opr�cz danych zawiera wska�nik na element nast�pny i element poprzedni. Dost�p do listy umosliwia wska�nik na jej pierwszy element. Mosliwe jest r�wnies zastosowanie wska�nika na ostatni element listy dwukierunkowej - przegl�danie listy mosna wykonywa� wtedy od przodu lub od ty�u. Wska�nik na nast�pny element w ostatnim elemencie listy ma warto�� NULL. Podobnie warto�� wska�nika na poprzedni element listy w pierwszym elemencie jest r�wna NULL. Niekt�re operacje wykonywane na li�cie dwukierunkowej s� prostsze nis na jednokierunkowej. Cen� jest jednak zaj�cie wi�kszej ilo�ci miejsca w pami�ci - kasdy element zamiast jednego wska�nika musi mie� dwa. Struktura odpowiadaj�ca elementowi listy dwukierunkowej ma nast�puj�c� posta�:
struct ListElem
Listy cykliczne
Listy cykliczne mog� by� jedno lub dwukierunkowe. R�sni� si� tym od zwyk�ych list, se wska�nik na nast�pny element w ostatnim elemencie nie ma warto�ci NULL, ale wskazuje na pocz�tek listy. Dodatkowo w li�cie cyklicznej dwukierunkowej, wska�nik na element poprzedni w pierwszym elemencie listy wskazuje na element ostatni. W przypadku list cyklicznych pocz�tek i koniec s� poj�ciami umownymi - mosna je odr�sni� tylko za pomoc� zewn�trznego wska�nika, kt�rego po�osenie mose si� dowolnie zmienia�. Struktury w j�zyku C odpowiadaj�ce elementom list cyklicznych s� takie same jak odpowiadaj�cych im list zwyk�ych.
Struktura logicza listy cyklicznej jednokierunkowej.
Struktura logiczna listy cyklicznej dwukierunkowej.
Stos
Stos jest bardzo cz�sto usywan� w programowaniu struktur�. Stos bywa nazywany r�wnies kolejk� LIFO (Last In First Out). Elementy ostatnio po�osone na stosie s� z niego zdejmowane przed elementami po�osonymi wcze�niej. Do obs�ugi stosu s�usy zmienna nazywana wska�nikiem stosu. Wska�nik stosu mose pokazywa� ostatnio po�osony element lub pierwsze wolne miejsce na stosie. Zdejmowany ze stosu jest element, na kt�ry wskazuje wska�nik stosu.
Stos mose by� implementowany za pomoc� tablicy. Wska�nikiem stosu jest wtedy zmienna b�d�ca indeksem w tablicy wskazuj�ca ostatnio po�osony na stosie element. Stos musi zapewnia� poprawne wykonanie przynajmniej dw�ch funkcji: Push (element) - po�osenie elementu na stosie, Pop() - zdj�cie elementu z wierzcho�ka stosu.
Stos mose by� r�wnies implementowany przy usyciu listy jednokierunkowej. Szczyt stosu znajduje si� wtedy na pocz�tku listy. Nowe elementy k�adzione na stos s� zawsze do��czane na pocz�tek listy. Elementy zdejmowane s� zawsze z pocz�tku. Implementacja stosu przy pomocy listy jest bardzo prosta i wygodna, dlatego jest cz�sto stosowana.
Kolejka
Kolejka jest dynamiczn� struktur� danych typu FIFO (First In First Out). Kolejka mose by� w prosty spos�b implementowana na li�cie jednokierunkowej przy pomocy dw�ch wska�nik�w - wska�nika na pocz�tek listy (jest to r�wnocze�nie wska�nik na pierwszy element, kt�ry zostanie z kolejki pobrany) oraz wska�nika na koniec listy (jest to miejsce, gdzie b�d� wstawiane elementy dopisywane do kolejki).
Drzewa
Drzewa s� strukturami hierarchicznymi i rekurencyjnymi. Mosna je podzieli� na drzewa mnogo�ciowe (kasdy w�ze� mose mie� dowoln� ilo�� potomk�w) lub najprostsze - drzewa binarne, gdzie kasdy w�ze� ma nie wi�cej nis dw�ch potomk�w. Przyk�ad drzewa binarnego przedstawia rysunek:
Wska�nik umosliwiaj�cy dost�p do ca�ego drzewa wskazuje na w�ze�, kt�ry nie jest niczyim potomkiem. W�ze� ten nazywa si� korzeniem drzewa. Kasdy w�ze� drzewa binarnego ma co najwysej dw�ch potomk�w - syn�w: lewego i prawego. Je�li pewien w�ze� nie ma jednego z potomk�w to odpowiedni wska�nik jest ustawiony na NULL. Rekurencyjno�� struktury drzewiastej polega na tym, se kasdy w�ze� mose by� rozpatrywany jako drzewo (cz�� zaznaczona w k�ku mose by� potomkiem korzenia), ale r�wnies mose by� traktowany tak jak osobne drzewo binarne. St�d algorytmy operuj�ce na strukturach drzewiastych s� najcz�ciej funkcjami rekurencyjnymi.
Struktura odpowiadaj�ce w�z�owi drzewa binarnego mose mie� posta�:
struct node
Drzewa binarne mog� by� usywane do przechowywania danych, kt�rych ilo�� mose si� zmienia� i dane te trzeba szybko wyszukiwa�. Dana, kt�ra ma zosta� znaleziona jest wtedy przechowywana w w�z�ach drzewa. Pierwsza informacja jest wstawiana jako korze� drzewa. Kolejne dane s� wstawiane tak, se w kasdym w�le dane mniejsze lub r�wne od danej w tym w�le znajduj� si� na lewo, natomiast wi�ksze - na prawo. Taka organizacja przyspiesza znacznie wyszukiwanie, poniewas chc�c sprawdzi� czy dana informacja istnieje, nie sprawdza si� wszystkich element�w, ale tylko jedn� �ciesk� w drzewie.
Wada tego typu reprezentacji polega na tym, se budowa drzewa, a wi�c r�wnies efektywno�� wyszukiwania, zalesy od kolejno�ci przychodzenia danych. W najgorszym przypadku drzewo wyszukiwa� mose si� zdegenerowa� do listy, nie b�dzie wi�c sadnych posytk�w z jego zastosowania. Aby unikn�� tego typu sytuacji stosuje si� tzw. drzewa AVL-wywasone (s� to zwyk�e drzewa binarne, ale algorytmy obs�ugi zapewniaj�, by prawe i lewe poddrzewo w kasdym w�le by�o mniej wi�cej tej samej wysoko�ci). Dok�adniejsze om�wienie przedstawionych tu problem�w mosne znale�� w ksi�sce:
N. Wirth 'Algorytmy + struktury danych = programy'
Przyk�adowe funkcje
Wstawianie elementu na pocz�tek listy jednokierunkowej
Operacja wstawiania
elementu na pocz�tek listy jednokierunkowej mose by� usyta do implementacji
operacji Push(element) na stosie. Cyfry na rysunku wskazuj� kolejno��
wykonywania operacji (zmian warto�ci wska�nik�w).

Przyk�adowa funkcja Push(element) mose mie� posta�:
void Push(Elem element)
le -> dana_1 = element;
le
-> nastepny = poczatek;
poczatek
= le;
return;
}
Wstawianie elementu na koniec listy jednokierunkowej
Operacja wstawiania
elementu na koniec listy jednokierunkowej mose by� wykorzystana do
implementacji kolejki FIFO.

Przyk�adowa funkcja Insert wstawiaj�ca element na ko�cu listy jednokierunkowej:
void Insert(Elem element)
le -> dana_1 = element;
le
-> nastepny = NULL;
koniec
-> nastepny = le;
koniec
= le;
return;
}
Kasowanie drzewa binarnego
void DelTree(struct node * root)
Wstawianie elementu do drzewa wyszukiwa�
void Insert(struct node ** root, char * name)
strcpy((* root) ->
dana1, name);
(*
root) -> left = (* root) -> right = NULL;
return;
}
if
(strcmp((*root) -> dana1, name) > 0)
Insert(& (*root) -> right, name);
else
Insert(& (*root) -> left, name);
return;
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 921
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved