| CATEGORII DOCUMENTE |
Universitatea Politehnica Bucuresti
Facultatea de Automatica si Calculatoare
Complemente de Informatica
Sistem de stiri
Introducere
Proiectul isi propune sa implementeze un sistem de stiri gen Google News. Acesta va colecta date din o serie de RSS-uri date si le va imparti pe domenii. Pentru o mai buna acuratete a impartirii pe clustere compararea stirilor s-a realizat cu ajutorul Wordnet.
Wordnet
Wordnet este o baza de date lexicala, disponibila online si care pune la dispozitie o varietate mare de termeni in limba engleza. Wordnet lucreaza cu 4 tipuri de parti de vorbire - substantive, verbe, adjective si adverbe si a fost gandit pentru a stabili conexiuni intre cuvinte. Un 'query' pentru un cuvant intoarce atat explicatia cat si o serie de sinonime. Conexiunile intre cuvinte se realizeaza prin traversarea unui arbore. Se intoarce o adancime care reprezinta distanta intre cele 2 cuvinte. Exista mai multe tipuri de relatii intre cuvinte si anume hipernime (relatie de tip is-a), holonim (relatie is-a-kind-of), meronime (relatie is-a-part-of).
Similaritate semantica
Pentru a verifica similaritatea a doua texte sunt necesari o serie de pasi :
impartire in tokeni
eliminare cuvinte de stop
stemming
calcularea similaritarii
Proiectul este realizat in Java si parcurge pe rand toti acesti pasi.
Implementare
In primul pas se citesc datele din RSS folosind libraria Rome. Apoi acestea sunt parsate si rezultatul se salveaza intr-o lista. Clasa RSSReader.java se ocupa de citirea si parsarea datelor. In partea de parsare se elimina si cuvintele de stop.
Stemming-ul se realizeaza prin algoritmul Porter. Clasa de baza care implementeaza algoritmul este Pstemmer.java, iar clasa Stemmer.java o adapteaza pentru a o integra in aplicatie.
Calculul similaritatii este implementat in clasa Similarity.java. Se calculeaza mai intai similaritatea intre doua stiri verificand pe rand similaritatile intre cuvinte. La acest pas se foloseste Wornet-ul pentru a determina distanta semantica dintre cuvinte .Valoarea similaritatilor este cumulata intr-o variabila si apoi este calculata o valoare medie. Aceasta valoare reprezinta similaritatea dintre cele doua stiri. Rezultatele similaritatii intre stiri se vor salva intr-o matrice pentru a fi folosite ulterior.
Pentru impartirea in clustere am folosit algoritmul Kmeans. Algoritmul consta in urmatorii pasi logici :
se specifica numarul de clustere dorite, k
se aleg aleator centrii clusterelor
se completeaza initial clusterii
se itereaza si in mod repetat se realoca instantele pentru a imbunatati impartirea
se opreste cand se converge sau dupa un numar fix de iteratii
Pasii in cod dupa ce in prealabil s-au calculat distantele intre texte:
Initializare centri.Se aleg aleator vectori pentru centri in metoda initCenters()
Asignare initiala. Se asigneaza vectorii intr-o ordine oarecare clusterilor
Recalculare centri. Se intra in bucla kmeans si se itereaza pana sunt indeplinite conditiile
Asignare vectori. A doua operatie in bucla, reasigneaza vectorii in functie de distantele fata de noii centri
Mai jos am adaugat un exemplu grafic cu pasii de functionare a algoritmului :
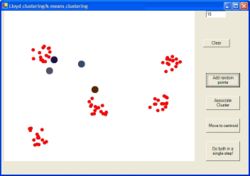
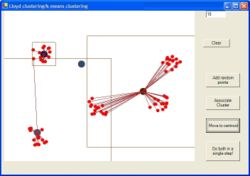
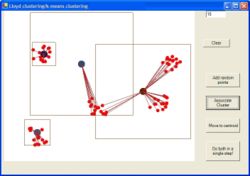
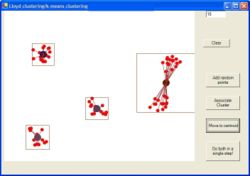
Pentru evaluarea distantei exista diverse metrici :
1)Euclidiana
2)Cosinus
3)WordNet
Am ales varianta Wordnet pentru ca se obtin cele mai bune rezultate pentru similaritate. Wornet returneaza numarul de noduri prin care se trece pentru a ajunge de la un cuvant la altul. Avand exemplul din figura:
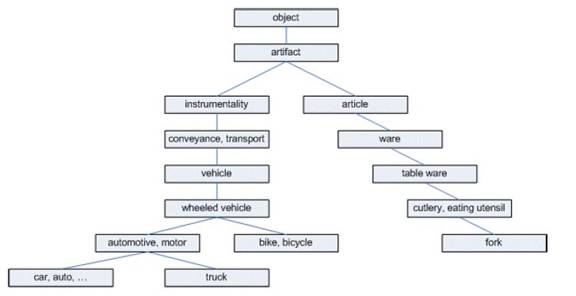
distanta intre cuvintele car si fork este 12.
Pentru a calcula similaritatea in functie de distanta dintre cuvinte exista mai multe formule. Formula folosita in proiect este :
sim(a, b) = 1/ dist(a, b)
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2456
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2026 . All rights reserved