| CATEGORII DOCUMENTE |
Compresia prin metoda LZW
Obiectivul lucrarii este studiul metodei de compresie bazata pe dictionar si experimentarea pe fisiere text.
1. Introducere
Este un algoritm ce sta la baza multor programe de compresie: compress and uncompress, din UNIX , sau gzip and gunzip, sau WinZip din Windows.
Algoritmul de compresie este de tipul lungime variabila - lungime fixa, in opozitie cu codarea Huffman (lungime fixa - lungime variabila). Desi exista mai multe versiuni ale algoritmului se pot distinge doua categorii: teoretica si practica. Diferenta dintre ele consta in faptul ca - in varianta teoretica - optimalitatea asimptotica se poate mai usor demonstra. Variantele practice pot fi mai usor de implementat.
Aceste metode constau / folosesc dintr-o serie de reguli de identificare a unor grupuri de simboluri si gruparea/depunerea lor intr-un dictionar care se asociaza sursei de informatie. Daca se intalneste un anumit grup de simboluri, se creaza un indicator (pointer) corespunzator locului ocupat de respectivul grup in dictionar. Cu cat se intalneste mai des un anumit grup de simboluri, cu atat este mai mare raportul de compresie. Deci, aceste metode codeaza siruri de simboluri de lungime variabila cu semne individuale, fiecare semn reprezentand un indicator (index) intr-un dictionar. Evident, se obtine o compresie atunci cand noile semne sunt de lungime mai mica.
Exemplu: Fie conventia reprezentarii unui cuvant dintr-o carte prin doua atribute:
(Numarul paginii) / (numarul cuvantului din pagina).
Atunci, mesajul "Titlul acestui capitol este compresia datelor" poate fi inlocuit prin
1/5 10/2 15/9 10/6 12/1
Cuvantul "Titlul" este inlocuit prin 500/3, ceea ce reprezinta al treilea cuvant din pagina 500. Cuvantul "compresia" este al 6 cuvant din pagina 10.
Marimea mesajului comprimat depinde de marimea dictionarului, deci de numarul de pagini si de numarul de inregistrari pe pagina. Daca aceste doua marimi se noteaza cu NP (numarul de pagini) si NR(numarul de inregistrari pe pagina) atunci numarul de biti pentru reprezentarea (codarea) unui cuvant din dictionar este
[log2(NP)] + [log2(NR)],
unde parantezele drepte arata rotunjurea la cel mai apropiat intreg.
Intrucat trebuie considerat si marimea mesajului de la intrare, exprimat prin numarul de simboluri, NS, rezulta un raport de compresie
![]()
Exemplu numeric: daca dictionarul contine 2200 pagini, sunt necesari log2(2200) = 11.03 -> 12 biti pentru a coda numarul paginii. Daca fiecare pagina contine un numar de cuvinte de 256 sunt necesari un numar de log2(256) = 8 biti pentru codarea fiecarui cuvant. Ca urmare, un cuvant oarecare din dictionar este codat pe 20 (=11+8) biti sau 2.5 -> 3 octeti. Mesajul comprimat va avea lungimea 20 biti * 6 cuvinte = 120 biti sau 18 octeti. In reprezentarea ASCII, cele 6 cuvinte necesita un total de (6+7+7+4+9+7) = 40 * 8 = 320 biti, deci 40 octeti. Raportul de compresie este
![]() sau
sau ![]()
Dictionarele pot fi statice sau adaptive. Un dictionar static este construit si transmis odata cu textul comprimat si este folosit ca referintele citate intr-o lucrare stiintifica. Un dictionar static este construit inaintea efectuariii compresiei si ramane neschimbat pe toata durata acesteia. Dictionarul static are avantajul ca poate fi "ales" ("acordat") in vederea codarii, inregistrarile care apar cu cea mai mare frecventa putand fi codate cu numarul cel mai mic de biti, in conformitate cu regulile de codare entropica. Dezavantajul folosirii unui dictionar static apare la compresia fisierelor mici, cand, din cauza transmisiei/memorarii atat a dictionarului cat si a fisierului comprimat, raportul de compresie nu este foarte bun, de multe ori chiar subunitar. De aceea, cei mai raspanditi sunt algoritmii de compresie bazati pe dictionare adaptive.
Un dictionar adaptiv consta in adaugarea unei abrevieri pe langa anumite grupe de simboluri, cand apar prima oara, si utilizarea in continuare doar a abrevierilor.
Cel mai folosit algoritm de compresie bazat pe dictionar este cel propus de Jacob Ziv si Abraham Lempel, in doua variante: prima din 1977, cunoscuta sub numele de LZ77, si - a doua, din 1978, cunoscuta sub numele de LZ78.
Algoritmul Lempel-Ziv-Welch
Idea de baza este de a imparti[1] secventa de intrare in blocuri (siruri) distincte de lungime diferita. Multimea blocurilor distincte defineste un dictionar. Indexul cuvintelor din dictionar este salvat in fisierul comprimat.
Algoritm de codare LZW:
Date intiale: Alfabetul A; secventa de intrare in;
#1. Initializeaza dictionarul cu simbolurile alfabetului;
#2. Initializeaza secventa comprimata: code ='';
#3. Citeste primul caracter de intrare, sirul prefix S: S = in(1);
#4. Cat Timp nu s-a parcurs toata secventa de intrare EXECUTA:
#4.1.Citeste urmatorul caracter de intrare: K = in(i+1).
#4.2. Daca sirul SK este in tabel
ATUNCI
#4.2.1. Asigneaza: S = SK;
ALTFEL
#4.2.2. Memoreaza SK in dictionar;
#4.2.3. Asigneaza: S = K;
#4.2.4. Scrie: code = code + code(S);
End #4.2;
End #5;
END.
3. Exemple
Exemplul - Se da secventa sub forma unui sir de
simboluri din alfabetul ![]() , de forma
, de forma ![]() . In urma rularii programului din anexa 2 se obtin
rezultatele:
. In urma rularii programului din anexa 2 se obtin
rezultatele:
D = 'a' 'b' 'ab' 'bb' 'ba' 'aa' 'abb' 'baa' 'aba' 'abba' 'aaa' 'aab' 'baab' 'bba'
code = '1' '2' '2' '1' '3' '5' '3' '7' '6' '6' '8' '4'
In ipoteza utilizarii codului ASCII pe 8 biti secventa de intrare are 23*8 = 181 biti. Secventa binara rezultata in urma comprimarii este 13 * 4 = 52 biti. Presupunand ca se cunoaste alfabetul si dictionarul, atat la emisie cat si la receptie, ar rezulta un raport de compresie
![]()
In realitate raportul de compresie este mai mic intrucat trebuie transmis si dictionarul folosit la codare. Raportul de compresie este imbunatatit cu cat fisierul de intrare este mai mare si cu cat exista mai multe date redundante.
Exemplul - Se da secventa sub forma unui sir de
simboluri din alfabetul ![]() de forma
de forma ![]() . Se obtin rezultatele:
. Se obtin rezultatele:
D = 'a' 'b' 'c' 'ab' 'ba' 'abc' 'cb' 'bab' 'baba' 'aa' 'aaa' 'aaaa'
code = '1' '2' '4' '3' '5' '8' '1' '10' '11'
Exemplul 3: Se da secventa sub forma unui sir de
simboluri din alfabetul ![]() de forma
de forma ![]() . In urma rularii programului din anexa 2 se obtin
rezultatele:
. In urma rularii programului din anexa 2 se obtin
rezultatele:
D = '/' 'W' 'E' 'D' 'T' 'B' '/W' 'WE' 'ED' 'D/' '/WE' 'E/' '/WEE' 'E/W' 'WEB' 'B/' '/WET'
code = '1' '2' '3' '4' '7' '3' '11' '12' '8' '6' '11'
Exemplul 4: Fie mesajul "abba_baba_buba" si dictionarul initializat cu alfabetul sursei, adica D=.
1). Initializare: code=, S=''; D=.
2). Citeste primul caracter: "abba_baba_buba"
![]()
3). Citeste urmatorul caracter "abba_baba_buba"
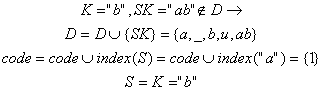
4). Citeste urmatorul caracter "abba_baba_buba"
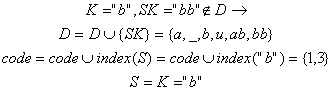
5). Citeste urmatorul caracter "abba_baba_buba"
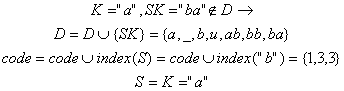
6). Citeste urmatorul caracter "abba_baba_buba"
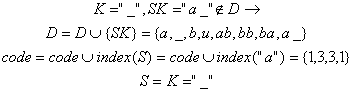
7). Citeste urmatorul caracter "abba_baba_buba"
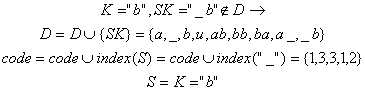
8). Citeste urmatorul caracter "abba_baba_buba"
![]()
9). Citeste urmatorul caracter "abba_baba_buba"
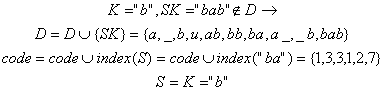
9). Citeste urmatorul caracter "abba_baba_buba"
![]()
10). Citeste urmatorul caracter "abba_baba_buba"
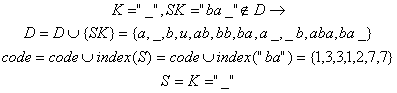
12). Citeste urmatorul caracter "abba_baba_buba"
![]()
13). Citeste urmatorul caracter "abba_baba_buba"
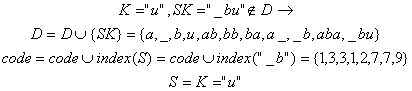
14). Citeste urmatorul caracter "abba_baba_buba"
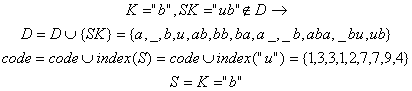
15). Citeste urmatorul caracter "abba_baba_buba"
![]()
Rezultatele finale sunt:
D
code
Presupunand ca se cunoaste alfabetul si dictionarul, atat la emisie cat si la receptie, ar rezulta un raport de compresie maxim
![]()
4. Concluzii
LZW este cunoscut ca facand parte din categoria algoritmilor de codare bazati pe dictionar sau substitutional. Algoritmul construieste un dictionar (denumit si tabel de translatie sau tabel de siruri) al datelor ce apar in fluxul de date ce trebuie comprimat. In fluxul de date se identifica forme de date (substrings) si memorate in intrarile dictionarului. Daca un subsir nu este prezent in dictionar, la momentul intalnirii sale, respectivul subsir se memoreaza si se codifica in dictionar. Codul alocat sub-sirului este scris in secventa de iesire, care este secventa comprimata. Cand se intalneste un subsir deja existent in dictionar, in secventa de iesire se scrie codul subsirului existent in dictionar.
Avantajul LZW este ca nu trebuie memorat dictionarul in vederea decodarii secventei comprimate, lucru avantajos in unele aplicatii.
Cand se comprima fisiere text, LZW initializeaza primele 256 intrari ale dictionarului cu codul ASCII ca fiind fraze (siruri de lungime 1). Mai departe, toate subsirurile sunt construite pe baza simbolurilor individuale, definite anterior.
Pentru secvente de intrare foarte mari lungimea dictionarului poate creste foarte mult. De aceea, in practica, dimensiunea dictionarului este limitata la 4096 cuvinte, ceea ce corespunde la o reprezentare a indexului (codul cuvintelor sir din dictionar) de 12 biti.
Daca indexul este reprezentat prin secvente binare de lungime variabila, atunci se obtine varianta lungime variabila-lungime variabila a algoritmului Lempel-Ziv.
Memo
Algoritmul LZ codifica pozitia prefixului urmat de ultimul caracter.
Algoritmul LZW codifica numai pozitia sirului in dictionar si numai pentru cuvinte(siruri) noi din dictionar.
5. Mod de lucru
5.1. Se studiaza si se ruleaza sursele Matlab pentru compresia LZW.
5.2. Se vor studia si rula sursele java scrise pentru codare.
5.3. Sa se experimenteze codarea aritmetica pe diverse marimi de fisiere de intrare (10 KB, 20KB, 100 KB). Ce probleme apar? Prezentati solutii de eliminare a acestora.
6. Tema de casa
Sa se scrie un program in cod Matlab pentru implementarea codarii si decodarii LZW aplicabile unui fisier text.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2981
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved