| CATEGORII DOCUMENTE |

Structurile de date folosesc date de tipuri diferite ce pot fi folosite in rezolvarea multor probleme.Problemele ce pot fi rezolvate cu structuri de date sunt din domenii diferite si pot fi realizate multe operatii cu acestea.
Tipurile de date structurate micsoreaza complexitatea programelor si le face mai inteligibile.
Data este o resursa la dispozitia programatorului .Orice limbaj de programare prermite folosirea mai multor tipuri de date . Indiferent de tipul de date ales , reprezentarea sa in memoria calculatorului fie interna, fie externa, se face printr-un sir de biti . Pentru a realiza aceasta reprezentare sunt implemetati algoritmi de codificare ce asigura corespondenta dintre tipul de data si sirul de biti , atat la scrierea datelor , cat si la citirea lor. Tipul de data ales de catre programator influenteaza calitatea programului, deoarece el determina dimensiunea zonei de memorie alocate , algoritmul de codificare si operatorii admisi pentru prelucrare.
Datele pot fi clasificate flosind mai multe criterii :
Cirteriul naturii datelor: de tip intreb, de tip real, de tip caracter, de tip logic.
Criteriul compunerii : date simple (date elementare), date compuse (date structurate , structuri de date).
Criteriul variabilitatii: constante , variabile.
Memoria interna a calculatorului este organizata ca un ansamblu de celule separate care au adrese consecutive.Intr-o astfel de celula sau intr-un grup de celule adiacente, se poate memora o data elementara.In acelasi mod este organizata si memoria externa: un ansamblu de locatii de memorare numite sectoare, care au adrese consecutive.
In cadrul unei aplicatii pot sa apara multe date de acelasi tip.De exemplu, o firma vrea sa prelucreze cu ajutorul calculatorului situatia vanzarilor.Informatia prelucrata va fi organizata logic intr-un tabel in care fiecare produs reprezinta un rand si fiecare zi dintr-o anumita perioada (saptamana, luna, an, etc) reprezinta o coloana.Acest mod de organizare permite o analiza rapida a informatiei si usureaza munca de obtinere a informatiilor statistice (volumul vanzarilor dintr-o zi, volumul vanzarilor pentru un produs intr-o anumita perioada, cel mai bine vandut produs intr-o anumita perioada, etc).Organizarea logica a informatiilor in exteriorul calculatorului trebuie sa se regaseasca si in interiorul lui, in modul in care sunt organizate datele sub forma de colectii de date care reprezinta informatiile.Utilizatorul unei aplicatii va gandi natural, fara sa fie preocupat de modul in care sunt organizate efectiv datele in memoria calculatorului. Asadar, colectia de date sau structura de date reprezinta o metoda de aranjare a datelor care sunt dependente unele de altele in cadrul unei aplicatii.
Pentru mai buna exemplificare a necesitatii folosirii unei structuri de date, vom lua drept exemplu o problema: Sa se calculeze mediile generale ale elevilor unei clase.
Procesul de calculare a mediilor generale ale elevilor unei clase presupune ca, pentru fiecare elev sa se calculeze mediile anuale la fiecare disciplina si apoi sa se calculeze media generala pe an.Sa presupunem ca exista 15 discipline.Procesul consta in executarea urmatorului program:
Pentru fiecare disciplina se aduna cele doua medii semestriale si se imparte la 2 pentru a se obtine media anuala;
Se aduna toate mediile anuale si rezultatul se imparte la numarul de discipline, adica 15, pentru a se obtine media generala;
Aceasta secventa de operatii se va executa repetat pentru fiecare elev din clasa.Datele necesare prelucrarii sunt:
Informatiile de intrare: sunt mediile semestriale la fiecare disciplina ale elevilor din clasa.Inseamna ca pentru fiecare elev din clasa va trebui sa existe un set de date de intrare format din mediile semestriale la fiecare disciplina (2x15=30 date de intrare);
Informatiile de iesire sunt mediile anuale la fiecare disciplina si media generala a elevilor din clasa.Inseamna ca pentru fiecare elev din clasa va trebui sa existe un set de date de iesire format din mediile anuale la fiecare disciplina si media generala (15+1=16 date de iesire);
In total, pentru fiecare elev ar fi necesare 46 de date elementare. Daca la acestea mai adaugam cel putin o data elementara necesara pentru identificarea elevului, iar in clasa sunt 25 de elevi, ar fi necesare 25x47=1175 de date elementare.Procesul de prelucrare a acestor date elementare presupune stabilirea a 1175 de triplete pentru descrierea lor, inclusiv definirea a 1175 de identificatori diferiti intre ei.Intr-un astfel de proces de prelucrare a datelor este mult mai convenabil ca datelor sa li se asocieze un model de organizare sub forma unui tabel, in care fiecarui elev ii corespunde un rand al tabelului, iar fiecarei medii, o coloana. Programatorul va fi degrevat de modul in care vor fi aranjate toate aceste date in memoria interna si de mecanismul de identificare a celor 1175 de date elementare.Prin acest model de organizare a datelor se construieste de fapt o structura de date.
Deci, structura de date este o colectie de date intre elementele careia se defineste un anumit tip de relatie care determina metodele de localizare si prelucrare a datelor.
Structura de date este o metoda de aranjare a datelor care sunt dependente unele de altele in cadrul unei aplicatii.Ea este o colectie de elemente pentru care s-a precizat:
Tipul elementelor;
Proprietatile de organizare a elementelor;
Regulile de acces la elemente;
Componentele unei structuri de date pot fi:
Date elementare;
Structuri de date;
O structua de date este o entitate de sine statatoare.Ea poate fi identificata printr-un nume, iar componentele ei isi mentin atributele. Fiecarei structuri de date ii este specific un anumit mecanism de identificare si de selectie a componentelor colectiei de date.Componentele structurii de date pot fi identificate prin:
Identificatorul (numele) componentei;
Pozitia pe care o ocupa componenta in cadrul structurii;
Structurile de date pot fi clasificate dupa diferite criterii:
In functie de tipul componentelor structurii:
Structuri omogene (componentele sunt de acelasi tip);
Structuri neomogene (componentele sunt de tipuri diferite);
In functie de modul de localizare a componentelor structurii:
Structuri cu acces direct (o componenta poate fi localizata fara sa se tina cont de celelalte componente ale structurii);
Structuri cu acces secvential (o componenta poate fi localizata numai daca se parcurg componentele care o preced in structura);
In functie de tipul de memorie in care sunt create:
Structuri interne (in memoria interna);
Structuri externe (in memoria externa);
In functie de timpul de utilizare:
Structuri de date temporare (pot fi organizate atat in memoria interna, cat si in memoria externa);
Structuri de date permanente (pot fi organizate numai in memoria externa);
In functie de stabilitatea structurii:
Structuri dinamice (in timpul existentei, in urma executarii unor procese, isi modifica numarul de componente si relatiile dintre ele);
Structuri statice (nu isi modifica in timpul existentei numarul de componente si relatiile dintre ele);
Asupra unei structuri de date se pot executa mai multe operatii care pot afecta valorile componentelor structurii si structura de date:
Crearea, prin care se realizeaza structura de date in forma initiala, pe suportul de memorare utilizat;
Consultarea, prin care se realizeaza accesul la componentele structurii in vederea prelucrarii valorilor acestora si a extragerii de informatii;
Actualizarea, prin care se schimba starea structurii astfel incat ea sa reflecte corect valoarea componentelor la un moment dat. Actualizarea se face prin trei operatii: adaugarea unor noi componente, stergerea unor componente, si modificarea valorii componentelor;
Sortarea, prin care se rearanjeaza componentele structurii in functie de anumite criterii de ordonare aplicate valorilor componentelor;
Copierea, prin care se realizeaza o imagine identica a structurii, pe acelasi suport sau pe suporturi diferite de memorare;
Mutarea, prin care se transfera structura, pe acelasi suport, la o alta adresa, sau pe un suport de memorare diferit;
Redenumirea, prin care se schimba numele structurii;
Divizarea, prin care se realizeaza doua sau mai multe structuri dintr-o structura de baza;
Reuniunea (concatenarea), prin care se realizeaza o singura structura de date, prin combinarea a doua sau mai multe structuri de date de acelasi tip;
Stergerea, prin care se distruge structura de date;
Implementarea unei structuri de date presupune:
Definirea structurii din punct de vedere logic, adica definirea componentelor, a relatiei dintre componente si a operatiilor care pot actiona asupra structurii;
Definirea structurii din punct de vedere fizic, adica a modului in care va fi reprezentata structura pe suportul de memorare;
Se pot folosi mai multe tipuri de structuri de date.Tipul de structura de date defineste apartenenta structurii de date la o anumita familie de structuri carora le corespunde acelasi mod de organizare logica, acelasi model de reprezentare fizica si care pot fi supuse acelorasi operatii.
Tipuri de structura de date defineste apartenenta structurii de date la o anumita familie de structure carora le corespunde acelasi mod de organizare logica, acelasi model de reprezentare fizica si care pot fi supuse acelorasi operatii
Dintre tipurile de structure de date fac parte :
Tabloruile de memorie ;
Fisierele.
Tabloul de memorie (array) este o structura de date interna format dintr-o multime ordonata de elemente , ordonarea facandu-se cu un ansamblu de indici.
Operatia de creare a unui tablou de memorie presupune:
Declararea tabloului de memorie pentru a I se aloca spatiu de memorie. Prin aceasta opertie , trebuie furnizate urmatoarele informatii :
o Numele tabloului care va fi folosit in expresii pentru a-l identifica;
o Tipul elementelor tabloului ;
o Dimensiunea tabloului pentru a preciza numarul de indici folositi pentru localizarea elementelor;
o Numarul de elemente ale tabloului pentru a se cunoaste spatiul de memorie care trebuie alocat tabelului .
Atribuirea de valori elementelor tabloului , care se face prin mai multe metode:
o Prin initializarea tabloului de memorie, la declararea lui;
o Prin introducerea valorilor de la tastatura;
o Prin preluarea valorilor dintr-o alta structura de date;
o Prin generarea valorilor folosind un algoritm de calcul al lor;
Este un tablou care contine elemente simple.Un tablou unidimensional este deci o suita de elemente, organizate dupa o cerinta data.Tabloul unidimensional se mai numeste si vector.
Putem reprezenta un tablou unidimensional in modul urmator:
In limbajul C++, sintaxa definirii unui tablou unidimensional este:
int nume_tablou[ numar_de_elemente ]
int reprezinta tipul elementelor pe care tabloul le contine(exemplu: un tablou in C++ este compus unic din elemente de acelasi tip);
nume_tablou reprezinta numele pe care decidem sa il dam tabloului, numele tabloului urmand aceleasi reguli ca o variabila oarecare;
numar_de_elemente reprezinta numarul maxim de elemente pe care tabloul le poate avea;
Exemplu:
int v[20]
-am declarat un vector cu numele "v" de tip intreg ce poate avea maxim 20 de elemente;
float a[10],b[40]
-am declarat un vector cu numele "a" de tip intreg care poate avea maxim 10 elemente si un vector cu numele "b" de tip intreg care poate avea maxim 40 de elemente;
Pentru a accesa un anumit element din vector trebuie sa apelam:
numele_tabloului[ pozitia ] , unde pozitia este locul pe care este situat elementul pe care dorim sa-l accesam;
pozitia primului element din vector este 1;
o pozitie este intotdeauna pozitiva;
indicele ultimului element este egal cu numarul maxim de elemente;
Exemplu:
Pentru a accesa elementul cu numarul 5 apelam functia nume_tablou[5].
Un element dintr-un tablou ( caracterizat de nume si pozitie ) poate fi manipulat exact ca o variabila, si se pot efectua operatii cu elementele acestuia:
pentru a atribui valoarea 6 elementului de pe pozitia 5 scriem:
v[5]=6;
pentru a atribui elementului de pe pozitia 9 suma elementelor de pe pozitiile 2 si 3 scriem:
v[9]= v[2] + v[3];
Atunci cand valorile elementelor nu sunt definite, trebuie sa le initializam, adica sa le dam o valoare:
v[1] = v[2] = v[3] = 0;
Aceasta inseamna citirea numarului n de componente, intr-un ciclu for, de pilda. De fapt avem de citit componenta numarului i, cu i de la 1 la n. Deci putem scrie:
int n,i,v[20];
cout<<"n=";
cin>>n;
for (i=1;i<=n;i++)
cout<<"v["<<i<<"]=";
cin>>v[i];
O alta metoda pentru citirea unui vector este:
v[10] =
-numarul de valori dintre acolade nu trebuie sa fie superior numarului maxim de elemente;
-valorile dintre acolade trebuie sa fie constante ( utilizarea variabilelor va provoca o eroare de compilare );
-daca numarul de valori dintre acolade este inferior numarului maxim de elemente, ultimele elemente vor avea valoarea 0;
-trebuie sa avem cel putin o valoare intre acolade;
De asemenea instructiunea urmatoare permite initializarea tuturor elementelor cu valoarea 0:
v[10] =
for(i=1;i<=n;i++)
cout<<v[i]<<" ";
Este un tablou care contine doua tablouri.De exemplu, un tablou bidimensional cu 3 linii si 4 coloane este un tablou cu 3 elemente, fiecare dintre ele fiind un tablou cu 4 elemente.Tablourile bidimensionale se mai numesc si matrici.
Putem reprezenta un tablou bidimensional in modul urmator:
In limbajul C++ sintaxa definirii unui tablou bidimensional este:
int nume_tablou [ numar_de_elemente_linie] [numar_de_elemente_coloana]
int reprezinta tipul elementelor pe care tabloul le contine;
nume_tablou reprezinta numele pe care decidem sa il dam tabloului,numele tabloului urmand aceleasi reguli ca o variabila oarecare;
numar_de_elemente_linie reprezinta numarul maxim de elemente pe care tabloul le poate avea pe linie;
numar_de_elemente_coloana reprezinta numarul maxim de elemente pe care tabloul le poate avea pe coloana;
Exemplu:
int v[10][15]
- am declarat o matrice cu numele "v" de tip intreg ce poate avea maxim 10 elemente pe linie si maxim 15 elemente pe coloana;
float v[12][23]
-am declarat o matrice cu numele "v" de tip real ce poate avea maxim 12 elemente pe linie si maxim 23 elemente pe coloana;
La fel ca si la tablourile unidimensionale trebuiesc indeplinite anumite conditii:
o pozitie este intotdeauna pozitiva;
indicele ultimului element este egal cu numarul maxim de elemente;
Exemplu:
Pentru a accesa elementul de pe linia 5 si coloana 2 apelam functia nume_tablou[5][2].
La fel ca si la vectori, un element dintr-o matrice poate fi manipulat exact ca o variabila, si se pot efecuta operatii cu el:
pentru a atribui valoarea 7 elementului de pe linia 5 si coloana 7 scriem:
v[5][7]=7;
pentru a atribui elementului de pe linia 9 si coloana 8 suma elementelor de pe linia 7 si coloana 10 si linia 8 si coloana 9 scriem:
v[9][8] = v[7][10] + v[8][9];
Initializarea unui tablou bidimensional element cu element:
numele_tabloului[0][0]=2;
numele_tabloului[0][1]=4;
Putem face aceasta citire utilizand un tablou bidimensional.Valorile elementelor le vom citi pozitie cu pozitie, utilizand doua instructiuni for:
int n,m,i,j,v[20][30];
cout<<"n=";
cin>>n;
cout<<"m=";
cin>>m;
for (i=1;i<=n;i++)
for(j=1;j<=m;j++)
cout<<"v["<<i<<"]["<<j<<"]=";
cin>>v[i][j];
for(i=1;i<=n;i++)
for(j=1;j<=m;j++)
cout<<v[i][j]<<" ";
Un tablou multidimensional este un tablou de tablouri.Dupa cum tabloul care contine doua tablouri se numeste bidimensional, tabloul ce contine mai multe tablouri se numeste multidimensional.
In limbajul C++ sintaxa definirii unui tablou multidimensional este:
int nume_tablou [ dim1 ] [ dim2 ][ dim3 ]
int reprezinta tipul elementelor pe care tabloul le contine;
nume_tablou reprezinta numele pe care decidem sa il dam tabloului, numele tabloului urmand aceleasi reguli ca o variabila oarecare;
dim1, dim2, dim3 reprezinta numarul maxim de elemente pe care tabloul le poate avea ;
Tablourile cu mai multi indici nu sunt eficiente la utilizare din cauza memoriei pe care o necesita (si care se aloca odata cu declararea lor). De exemplu, un tablou declarat int a[10][5][6] necesita 600 bytes de memorie.
Initializarea unui tablou bidimensional element cu element:
int nume_tablou [ dim1 ][ dim2 ].[ dim3 ] =
lista_valori este o lista cu elemente, separate prin virgula, de tip compatibil cu tipul de baza al tabloului.Indicele din dreapta este cel care variaza primul, iar cel din stanga ultimul pentru ca elementele din lista sa ocupe, unul cate unul, pozitiile componentelor din tablou;
se pot realiza initializari de tablouri cu dimensiune neprecizata urmand sa se creeze si sa se aloce memorie pentru un tablou de dimensiune suficient de mare pentru ca toate valorile initiale sa fie preluate;
Este o colectie de inregistrari legate intre ele. Toate inregistrarile despre elevii scolii pot forma un fisier. Prelucrarea datelor din fisier se poate face secvential sau in acces direct.Pentru a avea acces direct la o inregistrare, se poate alege unul dintre campuri pentru a identifica unic inregistrarea, (de exemplu, numarul matricol al elevului).
Inregistrarea poate fi si ea considerata o structura de date, in care elementele structurii sunt campuri. Accesul la elementele structurii se face prin numele campului.Din aceasta cauza sistemul trebuie sa aibe informatii explicite despre campuri, adica despre elementele care compun structura. Aceste informatii se refera la numele campului, tipul datelor memorate in camp si lungimea campului.
Asadar, fisierul este o structura de date in care elementele structurii sunt inregistrarile. Identificarea unui element se face printr-un numar de ordine numit numarul inregistrarii (record number). De exemplu, daca in scoala sunt 1500 de elevi, fisierul de date elev va avea 1500 de inregistrari, cate o singura inregistrare pentru fiecare elev, carora li se va atribui un numar unic de la 1 la 1500, in ordinea in care au fost scrise in fisier. Inregistrarea cu numarul 9 inseamna a noua inregistrare din fisier. Inregistrarea curenta este inregistrarea care se prelucreaza la un moment dat.
Fisierul (file) este o structura de date externa formata dintr-o multime ordonata de inregistrari, ordonarea facandu-se dupa numarul inregistrarii,(un numar atribut unic inregistrarii, atunci cand aceasta este adaugata la fisier).
Fisierul este memorat pe un suport de informatie. Suportul de informatie se numeste volum (volume).
De regula, pe un suport exista mai multe fisiere. Pentru a identifica un fisier, el trebuie sa aiba un nume (file name). Delimitarea fisierului pe suport se face prin marcaje logice:
marcaje de inceput de fisier
marcaje de sfarsit de fisier
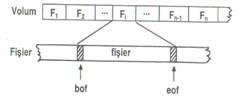
Limbajele care permit prelucrarea fisierelor pun la dispozitie utilizatorului doua functii prin care se poate testa daca inregistrarea curenta este marcajul de inceput sau de sfarsit de fisier.
Prelucrarea datelor dintr-un fisier presupune urmatoarele operatii:
1. Se deschide (open) fisierul de date. In urma acestei operatii i se atribuie o zona de lucru in memoria interna, in care se transforma de pe disc inreistrarile care se prelucreaza.tot in aceasta zona se pastreaza informatii despre starea fisierului e date: numarul total de inregistrari, numarul inregistrarii curente (inregistrarea care se prelucreaza la un moment dat ) etc.
2. Se exploateaza fisierul de date executandu-se diferite operatii de actualizare (adaugare, stergere, modificare) sau de consultare, Aceste operatii se realizeaza la nivel de inregistrare, adica, la un moment dat, nu se poate sterge, adauga sau modifica decat cate o singura inregistrare. Selectarea inregistrarii asupra carei actioneaza operatia de actualizare sau consultare se face prin mecanismul indicatorului de inregistrare care este o variabila de memorie in care se pastreaza numarul inregistrari curente. In general, limbajele folosite pentru dezvoltarea programelor de exloatare a fisierelor de date pun la dispozitie functii prin care furnizeaza numarul inregistrarii curente si numarul total de inregistrari din fisier. Exploatarea fisierului se desfasoara astfel:
Se cauta in fisierul de pe disc inregistrarea care urmeaza sa fie prelucrata (actualizata sau consulata).Identificarea ei se poate face dupa numarul ei.
Daca se gaseste inregistrarea,ea este copiata intr-o zona din memoria interna alocata de sistemul pentru prelucarea fisierului.
Se prelucreaza inregistrarea.
Daca operatia de prelucrare a fost o operatie de actualizare, inregistrarea este copiata din memoria interna pe disc, inlocuind vechea inregistrare.
3.Se inchide (close) fisierul de date cand se elibereaza zona de memorie alocata pentru lucru.
Prelucrarea inregistrarilor unui fisier se poate face in acces secvential sau in acces direct:
Accesul secvential prezinta mai multe dezavantaje.Unul dintre ele este acela ca,pentru reorganizarea fisierului intr-o anumite ordine,se consuma timp pentru operatia se sortare fizica a inregistrarilor,adica rearanjarea inregistrarilor pe suportul de informatie conform criteriului de ordonare dorit (de exemplu,in ordinea alfabetica a numelui elevilor).Un alt dezavantaj este acela ca timpul necesar pentru a se asigura accesul lao anumita inregistrare este mare.De exemplu,pentru a vea acces la inregistrarea elevului care are numarul de ordine 345,cautarea incepe cu inregistrarea cu numatl 000,continua cu 001,002 s.a.m.d pana se ajunge la numarul 345.
Accesul direct prezinta avantajul ca poate localiza rapid o inregistrare, in functie de valoarea unui camp stabilit pentru identificare.Accesul direct la inregistrarile fisierului presupune insa un anumit mod de organizare a datelor pe suport,care consuma mai mult suport de memorare descat cel secvential.Se recomanda folosirea accesului secvential,atunci cand aceeasi operatie se executa asupra unui numar mare de inregistrari din fisier si in cazul listarii unor rapoarte,iar accesul direct,in cazul in care se prelucreaza un numar mic de inregistrari care vor fi localizate dupa valoarea unui anumit camp.
Fisierul este o structura de date omogena ( este format din elemente de acelasi tip,adica din inregistrari), cu acces direct sau secvential (in functie de modul in care a fost organizat pe suportul de informatie), externa,permanenta sau dinamica.
In limbajul C++ sunt implementate doua tipuri de fisiere:
Fisiere text. Contin numai caractere reprezentate in codul ASCII, iar inregistrarea este o linie de text.
Fisiere binare. Inregistrarile sunt de acelasi tip (fie date elementare de tip int, float etc.), fie structuri de date organizate sub forma unei colectii de campuri.
Daca declararea fluxurilor de date standard este implementata in bibliotecile sistemului (fisierul antet iostream.h), pentru celelalte fisiere trebuie declarat fluxul de date.In programele in care lucrati cu fluxuri de date pentru fisiere trebuie sa includeti fisierul antet fstream.h cu intructiunia pentru preprocesor:
#include<fstream.h>
Declararea unui flux de date pentru un fisier se face cu instructiunea:
fstream nume_logic (nume_fizic, mod_de_deschidere);
Unde nume_logic este un identificator care se va folosi in program pentru a face referiri la acel fisier, nume_fizic este o constanta de tip sir de caractere care reprezinta numele fizic al fisierului (identificatorul sau complet pentru sistemul de operare,care va contine inclusiv calea de director, daca fisierul nu se gaseste in directorul curent), iar mod_de_deschidere este o construcite de forma : ios::constanta_intreaga
Sau mai multe constructii de aceasta forma legate de operatorul sau logic pe biti (|) , unde ios:: permite accesul la aceste constante.
Aceasta instructiune realizeaza urmatoarele:
creeaza fluxul de date intre fisier si program;
deschide fisierul;
conecteaza fisierul la fluxul de date.
De exemplu, cu instructiunile:
fstream f1 ('c://alfa.txt',ios::in)
fstream f2 ('c://beta//alfa.txt',ios::app)
se deschid doua fluxuri de date pentru doua fisiere care vor fi conectate la aceste fluxuri: un flux pentru fisierul alfa.txt care se gaseste in directorul radacina al discului C , referirea lui in program facandu-se cu identificatorul f1, si un flux pentru fisierul alfa.txt care se gaseste in subdirectorul beta din directorul radacina al discului C , referirea lui in program facandu-se cu identificatorul f2.Fisierul f1 este deschis numai pentru operatia de citire, iar fisierul f2 numai pentru operatia de adaugare.
Cu instructiunea :
fstream f1 ('alfa.txt', ios::in) , f2 ('beta.txt', ios::out)
se deschid doua fluxuri de date pentru doua fisiere care vor fi conectate la aceste fluxuri: un flux pentru fisierul alfa.txt , referirea lui in program facandu-se cu identificatorul f1, si un flux pentru fisierul beta.txt, referirea lui in program facandu-se cu identificatorul f2.Ambele fisiere se gasesc in directorul curent.Fisierul f1 este deschis numai pentru operatia de citire, iar fisierul f2 numai pentru operatia de scriere.
In prelucrarea unui fisier text va sunt utile urmatoarele functii de sistem :
eof() - se foloseste pentru a detecta sfarsitul unui fisier. Daca valoarea citita in pozitia curenta este codul ASCII pentru sfarsit de fisier, functia furnizeaza valoarea 1, altfel furnizeaza valoarea 0.
close() - inchide un fisier deschis;
tellp()/tellg() - furnizeaza pozitia pointerului fata de inceputul fisierului la scriere,respectiv la citire. Rezultatul furnizat este de tip long.
seekp(x,y)/seekg(x,y) - deplaseaza pointerul in pozitia precizata la scriere,respectiv la citire.Parametrul x reprezinta deplasarea fata de o pozitie de referinta precizata prin parametrul y (care este o constanta se sistem si care poate avea una dintre valorile : beg- inceput de fisier; cur- pozitia curenta sau eof - sfarsit de fisier.Parametrul x este de tip lond si poate avea valori pozitive (deplasarea se face la dreapta pozitiei de referinta) sau negative (deplasarea se face la stanga pozitiei de referinta).
clear - stabileste starea fluxului de date la valoarea precizata.Parametrul x este de tip intreg.Daca are valoare 0,starea fluxului este buna (se poate executa o operatie de citire).Daca are valoare 1 inseamna ca s-a ajuns la sfarsitul fisierului.
get (x,n,'d') - extrage un caracter dintr-un sir de caractere x pana se intampla unul dintre evenimentele urmatoare: a intalnit marcaj de sfarsit e linie sau marcajul de sfarsit de fisier, au fost citite n caractere sau a citit caracterul folosit ca delimitator 'd';
get() - extrage urmatorul caracter sau marcajul de sfarsit de fisier;
getline(x,n,'d') - are acelasi efect ca si get9x,n,'d'), cu deosebire ca extrage si delimitatorul de sfarsit de linie ('/n' sau 'd').
Apelarea acestor functii se face cu o constructie de forma:
nume_logic_fisier.nume_functie();
Functiile din biblioteca pentru fluxurile de date sunt implementate folosind programarea orientata pe obiecte. Din aceasta cauza, la apelarea lor folositi operatori a caror semnificatie nu a fost definita si nu poate fi definita, neavand cunostinte despre programarea orientata pe obiecte (cum sunt de exemplu operatorii '.' si '::'). Retineti doar ca acesti operatori au prioritate maximam. Mai retineti ca accesul la orice constanta de sistem se face prin constructia: ios::constanta_intreaga
Pentru citirea datelor de la tastatura si scrierea lor intr-un fisier text se folosesc doua fluxuri de date:
a. Fluxul de date al tastaturii (cin>>ch) - pentru citire de la tastatura:
* sursa este tastatura (fisierul standard cin);
* destinatia este o variabila de memorie (ch);
b. Fluxul de date al fisierului (f<<ch) - pentru scriere in fisier :
* sursa este variabilka de memorie (ch);
* destinatia este fisierul (f);
Secventa de instructiuni folosita este:
char ch, nume[20];
cout<<'nume fisier=';
cin>>nume;
ftream f(nume, ios::out)
while (cin>>ch) f<<ch;
f.close();
Pentru citirea datelor din fisier si scrierea lor pe ecranul monitorului se folosesc doua fluxuri de date
Fluxul de date al fisierului (f>>ch) - pentru citire din fisier:
o sursa este fisierul (f);
o destinatia este o variabila de memorie (ch);
2. Fluxul de date al monitorului (cout<<ch) - pentru scriere pe ecran :
sursa este variabila de memorie (ch);
destinatia este monitorul (fisierul standard cout)
Secventa de intructiuni folosita este:
char ch, nume [20];
cout<<'nume fisier=';
cin>>nume;
fstream f(nume, ios::in);
while (f>>ch)
cout<<ch;
f.close ();
a)Vector:
#include<iostream.h>
void main()
for(i=1;i<=n;i++)
if ( v[i] > max )
max=v[i];
cout<<"Maximul elementelor din vector este:"<<max;
b) Matrice:
#include<iostream.h>
void main()
for(i=1;i<=n;i++)
for(j=1;j<=m;j++)
if ( v[i][j] > max )
max=v[i][j];
cout<<"Maximul elementelor din matrice este:"<<max;
Pentru minim,variabila "min" trebuie initializata cu o valoare cat mai mare, iar conditia trebuie schimbata in "v[i] < max".
Daca vrem sa afisam pozitia pe care este situat maximul, sau minimul va trebui sa afisam i in cazul vectorilor si i,j in cazul matricilor.
Se citeste un tablou cu n linii si n coloane.Se cere sa se afiseze elementele tabloului in ordinea rezultata prin parcurgerea acestuia in spirala, incepand cu primul element din linia 1, in sensul acelor de ceas.
Exemplu:

![]()
![]() 1 2 3
1 2 3
![]()
![]() 7 8 9
7 8 9
![]() 4 5 6
4 5 6
Rezolvare:
#include <iostream.h>
main ()
for(k=1;k<=n/2+1;k++)
Rezolvare:
#include <iostream.h>
void main(void)
cout<<'Elementele matricei A sunt: '<<endl;
for(i=1;i<=n;i++)
cout<<'m = ';cin>>m;
cout<<'p = ';cin>>p;
for(i=1;i<=m;i++)
for(j=1;j<=p;j++)
cout<<'Elementele matricei B sunt: '<<endl;
for(i=1;i<=m;i++)
for(i=1;i<=n;i++)
for(j=1;j<=p;j++)
for(k=1;k<=m;k++)
c[i][j]+=a[i][k]*b[k][j];
cout<<'Elementele matricei produs '<<endl;
for(i=1;i<=n;i++)
Se folosesc identificatorii:
- variabila ch pentru citirea si scrierea unui caracter si variabilele nume1 pentru numele fisierului in care se adauga al doilea fisier si nume2 pentru numele fisierului care se adauga;
- f1, f2 si f3 pentru fluxutile de date ale fisierelor : f1 pentru fisierul in care se adauga , f2 pentru fisierul care se adauga si f3 pentru fisierul rezultat pentru a fi citit.
#include<iostream.h>
#include<fstream.h>
#include<iomanip.h>
void main()
Fundamentele Programarii - culegere de probleme pentru clasa a IX-a. Autori: Dana Lica, Mircea Pasoi.Editura L&S Info;
Fundamentele Programarii - culegere de probleme pentru clasa a X-a. Autori: Dana Lica, Mircea Pasoi.Editura L&S Info;
Informatica - Caiet de laborator pentru clasa a X-a.Autor: Carmen Minca. Editura L&S Info;
C++ - Probleme rezolvate si algoritmi.Autor: Doina Hrinciuc Logofatu. Editura Paralela 45;
Informatica - Teste grila C/C++. Autori: Ana Intuneric, Cristina Sichim. Editura ALL;
https://www.runceanu.ro/adrian/curs/progr2005/laborator%205%20-programarea%20calc%202005.pdf
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2689
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2026 . All rights reserved