| CATEGORII DOCUMENTE |
Structurarea programelor - Definirea si initializarea datelor
Operatori
Capitolul curent si cel urmator sunt dedicate limbajului de asamblare. Pe langa instructiunile propriu-zise, un program ASM poate cuprinde directive, prin intermediul carora se definesc date, etichete si proceduri, se structureaza segmente, se definesc si se utilizeaza macroinstructiuni, se controleaza in general procesul de asamblare etc. Directivele nu reprezinta instructiuni, ci comenzi catre asamblor, efectul lor manifestandu-se exclusiv in faza de asamblare.
1 Segmentare. Directive pentru definirea segmentelor
Un modul de program in limbajul de asamblare poate conduce la:
. o portiune dintr-un segment;
. un segment;
. portiuni de segmente diferite;
. mai multe segmente.
Mai multe module obiect se leaga prin operatia de link-editare.
1.1 Directivele SEGMENT si ENDS
Indiferent de modul de dezvoltare al unui program ASM, atat instructiunile, cat si datele trebuie sa se gaseasca in interiorul unui segment. Directiva SEGMENT controleaza:
. numele segmentului;
. alinierea;
. combinarea cu alte segmente;
. continuitatea (adiacenta) segmentelor.
Forma generala a directivei SEGMENT este:
nume SEGMENT [tip_aliniere] [tip_combinare] ['nume_clasa']
nume ENDS
Parametrii inclusi in paranteze drepte sunt optionali. Daca sunt prezenti, acestia trebuie sa fie in ordinea specificata. Semnificatia parametrilor este:
. tip_aliniere - specifica la ce limita va fi relocat segmentul in memorie; poate avea una din formele:
. PARA (implicit) - aliniere la paragraf (segmentul fizic, adica adresa pe 20 de biti, va fi relocat la prima adresa absoluta divizibila prin 16);
. BYTE - fara aliniere (segmentul se va reloca la urmatorul octet liber);
. WORD - aliniere la cuvant (segmentul se va reloca la urmatorul octet liber aflat la adresa para);
. DWORD - aliniere la dublu-cuvant (segmentul se va reloca la prima adresa divizibila cu 4);
. PAGE - aliniere la pagina (segmentul se va reloca la prima adresa absoluta divizibila prin 256).
Sa consideram urmatoarele definitii de segmente:
DAT1 SEGMEMT BYTE
X1 db 7 dup (?)
DAT1 ENDS
DAT2 SEGMENT WORD
x21 dw 300 dup (?)
x22 dw ?
DAT2 ENDS
DAT3 SEGMENT PARA
x3 db 5 dup (?)
DAT3 ENDS
Daca prima adresa disponibila este 1000H, cele trei segmente vor fi relocate la urmatoarele adrese fizice:
DAT1 1000:0 - 1000:6
DAT2 1000:8 - 1000:261
DAT3 1027:0 - 1027:4
Adresele de segment se obtin prin trunchierea la primele patru cifre ale adresei fizice de inceput, iar
offset-urile se calculeaza corespunzator. Offset-urile la executie difera in general de offset-urile la asamblare. Offset-ul la asamblare pentru x21 este 0, dar la executie este 8.
Operatorul OFFSET, care furnizeaza deplasamentul unei variabile sau unei etichete in cadrul unui segment, va produce offset-ul de la executie. Instructiunea:
mov bx, OFFSET x21
va incarca in BX valoarea 8.
Daca dorim ca offset-ul la asamblare sa coincida cu offset-ul la executie, putem folosi tipul de aliniere PARA (ultima cifra a adresei fizice de inceput a segmentului este 0).
. tip_combinare - specifica daca si cum se va combina segmentul respectiv cu alte segmente, la operatia
de link-editare; poate fi:
. necombinabil (implicit) - nu se scrie nimic;
. PUBLIC - segmentul curent va fi concatenat cu alte segmente cu acelasi nume si cu atributul PUBLIC. Aceste segmente pot fi in alte module de program. Se va forma, deci, un singur segment final cu numele respectiv, cu o unica adresa de inceput; lungimea unui segment cu atributul PUBLIC este suma lungimilor segmentelor cu acelasi nume.
. COMMON - specifica faptul ca segmentul curent si toate segmentele cu acelasi nume si tipul COMMON se vor suprapune in memorie (incep la aceeasi adresa fizica); lungimea unui segment COMMON este cea mai mare lungime a segmentelor componente;
. STACK - marcheaza segmentul curent ca reprezentand stiva programului; daca sunt mai multe segmente cu tipul STACK, ele vor ti tratate ca la PUBLIC; urmatorul exemplu este o definire si o initializare explicita a unui segment de stiva:
stiva SEGMENT STACK
db 256 dup (?)
stiva_sp label WORD
stiva ENDS
cod SEGMENT
mov ax, stiva
mov ss, ax
mov sp, OFFSET stiva_sp
cod ENDS
. AT EXPRESIE - specifica faptul ca segmentul va fi plasat la o adresa fizica absoluta de memorie; urmatorul exemplu ilustreaza definirea explicita a tabelei de vectori de intreruperi:
INT_TABLE SEGMEMT AT 0
dd PROC_NIV_0
dd PROC_NIV_1
IMT_TABLE ENDS
Aceste forme se folosesc cand programul este dezvoltat pentru echipamente dedicate. In cazul unui calculator de tip IBM-PC, exista functii DOS pentru accesul la tabela de intreruperi.
. 'nume_clasa' - specifica un nume de clasa pentru segment, extinzand astfel numele segmentului; de exemplu, daca segmentul are si atributul 'nume_clasa', atunci atributele COMMON sau PUBLIC vor actiona numai asupra segmentelor cu acelasi nume si acelasi nume de clasa; ca nume de clase, se folosesc de obicei 'code', 'data' si 'stack'.
Sa consideram doua module ASM, asamblate distinct. In primul modul, avem urmatoarele definitii de segmente:
dseg1 SEGMENT PARA PUBLIC 'data'
db 100 dup (?)
dseg1 ENDS
dseg2 SEGMENT PARA COMMON
db 50 dup (?)
dseg2 ENDS
cseg SEGMENT PARA PUBLIC 'code'
db 20 dup (?)
cseg ENDS
In al doilea modul, exista urmatoarele definitii:
dseg1 SEGMENT PARA PUBLIC 'data'
db 30 dup (?)
dseg1 ENDS
dseg2 SEGMENT PARA COMMON
db 200 dup (?)
dseg2 ENDS
cseg SEGMENT PARA PUBLIC 'code'
db 70 dup (?)
cseg ENDS
Imaginea segmentelor rezultate in urma link-editarii si a relocarii este cea din Figura 1.
1.2 Directiva ASSUME
Directiva ASSUME realizeaza o conexiune simbolica (logica) intre definirea instructiunilor si a datelor in segmente logice (cuprinse intre SEGMENT si ENDS) la momentul asamblarii si accesul, la executie, la instructiuni si date prin registrele de segment. Are forma generala:
ASSUME reg_seg:expresie,
in care reg_seg este un registru de segment, iar expresie poate fi;
. un nume de segment;
. un nume de grup de segmente;
. SEG nume segment;
. NOTHING.
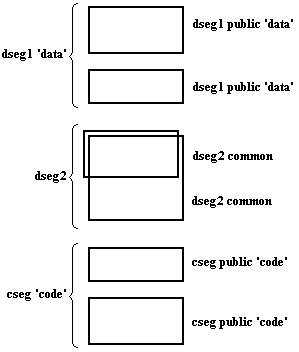
Figura 1 Combinarea segmentelor este controlata de directiva SEGMENT
In aceeasi directiva ASSUME se pot asocia mai multe registre de segment, de exemplu:
ASSUME CS:CSEG, DS:DSEG1, ES:DSEG2, SS:SSEG
Directiva ASSUME nu ne scuteste de incarcarea registrelor de segment cu adresele de segment. Daca un nume de segment nu apare intr-o directiva ASSUME, datele definite in acel segment pot fi accesate numai prin prefixe de segment. Sa consideram urmatorul exemplu:
dseg SEGMENT
BETA dw 5
dseg ENDS
cseg SEGMENT
ASSUME cs:cseg, es:dseg
mov ax, dseg
mov es, ax
mov bx, BETA ; se va genera o instructiune MOV,
; cu adresare prin registrul ES
; conform asocierii ES:dseg
cseg ENDS
Daca nu s-ar fi asociat registrul ES cu segmentul dseg prin directiva ASSUME, accesul la variabila BETA trebuia scris in forma:
mov bx, es:BETA
In formatul intern al instructiunii (in codificare), trebuie sa apara prin ce registru de segment se calculeaza adresa fizica. Daca simbolul care apare intr-o instructiune (de exemplu, BETA), face parte dintr-un segment care este asociat printr-o directiva ASSUME, cu un registru de segment, atunci se va codifica intern accesul prin acel registru de segment (in cazul de fata, prin ES). Codificarea registrului de segment se face:
. implicit - datele sunt accesate in toate modurile de adresare prin registrul DS, cu exceptia celor care implica registrul BP, caz in care se foloseste SS, iar instructiunile sunt adresate totdeauna prin CS;
. explicit - prin utilizarea prefixelor de segment.
1.3 Directiva GROUP
Directiva GROUP serveste la gruparea mai multor segmente (inclusiv cu nume si atribute diferite), a caror lungime totala nu depaseste 64 KO, sub acelasi nume. Are forma generala:
nume_grup GROUP nume_seg1, nume_seg2,
Aceasta directiva reprezinta o alta modalitate de combinare a mai multor segmente, pe langa cea oferita de atributul PUBLIC.
Numele de grup se poate folosi in directive ASSUME, la initializarea unor registre de segment sau la calculul unui offset. Sa consideram urmatorul exemplu:
d1 SEGMENT
y dw 20
d1 ENDS
d2 SEGMENT
x db 2
d2 ENDS
data GROUP d1, d2
Putem scrie instructiuni de forma:
mov ax, data
mov ds, ax
mov ax, OFFSET x
mov ax, OFFSET data:x
sau directive de forma:
ASSUME ds:data
Expresia OFFSET x furnizeaza offset-ul variabilei x in cadrul segmentului d1, iar expresia OFFSET data:x produce offset-ul variabilei x in cadrul grupului de segmente data.
2 Definirea simplificata a segmentelor
Aceasta modalitate de definire este introdusa in variantele recente ale asambloarelor. Avantajul major este faptul ca se respecta acelasi format (structura a programului obiect) ca si la programele dezvoltate in limbaj de nivel inalt. Concret, daca utilizam definirea simplificata, se vor genera segmente cu nume si atribute identice cu cele generate de compilatoarele de limbaje de nivel inalt. Toate directivele simplificate incep cu un punct.
2.1 Modele de memorie
Directiva pentru specificarea modelului de memorie are forma generala:
.model tip
in care tip poate fi tiny, small, medium, large sau huge. Semnificatia acestor tipuri este:
. tiny - toate segmentele (date, cod, stiva) se pot genera intr-un spatiu de 64KO si formeaza un singur grup de segmente. Se foloseste la programele de tip COM. Toate salturile, apelurile si definitiile de proceduri sunt implicit de tip NEAR;
. small - datele si stiva sunt grupate intr-un singur segment, iar codul in alt segment. Fiecare din acestea nu trebuie sa depaseasca 64KO. Toate salturile, apelurile si definitiile de proceduri sunt implicit de tip NEAR;
. medium - datele si stiva sunt grupate intr-un singur segment (cel mult egal cu 64KO), dar codul poate fi in mai multe segmente separate (nu se grupeaza), deci poate depasi 64KO. Salturile si apelurile sunt implicit tip FAR, iar definitiile de proceduri sunt implicit de tip far.
. compact - codul generat ocupa cel mult 64KO (se grupeaza), dar datele si stiva sunt in segmente separate (pot depasi 64KO). Apelurile si salturile sunt implicit de tip NEAR. Se utilizeaza adrese complete (segment si offset) atunci cand se acceseaza date definite in alte segmente.
. large - atat datele, cat si codul generat pot depasi 64KO.
. huge - este asemanator modelului large, dar structurile de date pot depasi 64KO; se utilizeaza adrese complete normalizate in care offset-ul este redus la minim (in domeniul 0 - 15), ceea ce face ca o adresa fizica sa fie descrisa de o unica pereche (segment, offset). La modelele compact si large, o structura compacta de date (de tip tablou) nu poate depasi limitele unui segment fizic (64KO); la modelul huge, aceasta restrictie dispare.
Folosirea directivelor simplificate prezinta si avantajul ca nu mai sunt necesare directive ASSUME: asocierile intre segmentele generate si registrele de segment sunt implicite.
Se utilizeaza urmatoarea terminologie:
. modele de date mici: small, compact;
. modele de cod mic: small, medium;
. modele de date mari: medium, large, huge;
. modele de cod mare: compact, large, huge.
2.2 Directive simplificate de definire a segmentelor
Formele generale ale acestor directive sunt:
. .stack dimensiune
. .code [nume]
. .data
. .data? ; date neinitializate in l.n.i
. .fardata [nume] ; segmente de date utilizate prin
. .fardata? [nume] ; adrese complete in l.n.i
. .const ; definire de constante in l.n.i
Daca parametrul nume lipseste, se atribuie nume implicite segmentelor generate, dupa cum urmeaza:
. pentru .code TEXT (la modele de cod mic) sau nume_fisier_sursa_TEXT (la modele de cod mare);
. pentru .data? _BSS;
. pentru .data DATA;
. pentru .const CONST
. pentru .stack STACK
. pentru .fardata _FAR_DATA
. pentru .fardata? _FAR_BSS
Se genereaza grupul de segmente DGROUP. Acesta cuprinde:
. toate segmentele, la modelul de date tiny;
. DATA, _BSS, CONST, STACK, in rest.
Se considera ca exista o directiva ASSUME implicita (care nu mai trebuie, deci, scrisa in textul sursa), de forma:
. la modelele small si compact:
ASSUME cs:TEXT, ds:DGROUP, ss:DGROUP
. la modelele large si huge:
ASSUME cs:nume_TEXT, ds:DGROUP, ss:DGROUP
; nume este numele din directiva .code
; sau numele fisierului sursa
. la modelul de memorie tiny:
ASSUME cs:DGROUP, ds:DGROUP, cg:DGROUP
Daca se folosesc directivele .fardata si / sau .fardata?, atunci segmentele respective trebuie gestionate explicit prin directive ASSUME.
Adresele de inceput ale segmentelor si ale grupurilor de segmente definite cu directivele simplificate sunt disponibile prin simbolurile globale:
@data, @data?, @fardata, @fardata?, dgroup.
Daca in acelasi text sursa (model de cod mare) se folosesc mai multe directive .code cu nume diferite, atunci, pana la intalnirea unei alte directive de segment, este ca si cum s-ar fi scris o directiva ASSUME CS: cu numele respectiv.
Segmentele generate au numele de clasa 'STACK', 'CODE', 'DATA', 'BSS', 'FAR_BSS', 'FAR_DATA'. Segmentul CONST are numele de clasa DATA.
Tipurile de combinare sunt:
. PUBLIC (la .code, .data, .data? si .const);
. STACK (la .stack);
. fara combinare (la .fardata si .fardata?).
Tipul de aliniere este PARA (pentru .stack, .fardata si .fardata?) si WORD (pentru celelalte).
Sa consideram fisierul sursa exemplu.asm, cu continutul de mai jos:
.model large
.data
.const
.stack 256
.data?
.fardata
.fardata?
.code
end
Fisierul listing generat cuprinde (intre altele), urmatoarele informatii:
SymbolName Type Value
??DATE Text '06/02/96'
??FILENAME Text 'exemplu'
??TIME Text '15:21:50'
??VERSIOM Number 0200
@CODE Text EXEMPLU_TEXT
@CODESIZE Text 1
@CPU Text 0101H
@CURSEG Text EXEMPLU_TEXT
@DATA Text DGROUP
@DATASIZE Text 1
@FARDATA Text FAR_DATA
@FARDATA? Text FAR_BSS
@FILENAME Text EXEMPLU
@MODEL Text 5
@WORDSIZE Text 2
Groups & Segments Bit Size Align Combine Class
DGROUP Group
CONST 16 0000 Word Public DATA
STACK 16 0100 Para Stack STACK
_BSS 16 0000 Word Public BSS
_DATA 16 0000 Word Public DATA
EXEMPLU_TEXT 16 0000 Word Public CODE
FAR_BSS 16 0000 Para none FAR_BSS
FAR_DATA 16 0000 Para none FAR_DATA
Listingul releva o serie de simboluri predefinite si valorile asociate. Se remarca adresele de inceput ale segmentelor, cel mai important fiind simbolul @DATA care are aceeasi valoare cu adresa grupului DGROUP. Partea a doua a listingului descrie segmentele si grupurile de segmente.
Initializarea registrelor DS si ES la inceputul unui program principal se poate face cu simbolul @DATA sau cu simbolul DGROUP. Macroinstructiunea init_ds_es realizeaza operatia:
mov ax, dgroup
mov ds, ax
mov es, ax
3 Directive pentru legarea modulelor
Cand programul dezvoltat se compune din mai multe module asamblate separat, este necesara specificarea simbolurilor care sunt definite intr-un modul si utilizate in alte module. Aceste simboluri sunt nume de variabile, etichete sau nume de proceduri. In mod normal, un simbol este vizibil doar in modulul in care este definit (simbol local). Simbolurile care sunt vizibile in mai multe module de program se numesc simboluri globale.
Se folosesc urmatoarele notiuni:
. simboluri publice - sunt simboluri care sunt definite intr-un modul curent de program si folosite (eventual) si in alte module; aceste simboluri se declara ca simboluri publice in modulul in care sunt definite;
. simboluri externe - sunt simboluri care sunt folosite intr-unul din modulele in care nu sunt definite; aceste simboluri se declara ca simboluri externe in modulele in care sunt folosite.
Se observa ca un simbol global trebuie declarat ca simbol public in modulul in care este definit si ca simbol extern in modulele in care este folosit, altele decat cel in care este definit.
Declaratia unui simbol ca simbol public, respectiv extern se face cu directivele PUBLIC, respectiv EXTRN.
Directiva PUBLIC are forma generala:
PUBLIC nume, nume,
Simbolurile declarate ca publice pot fi variabile, etichete, nume de proceduri sau constante numerice simbolice.
Directiva EXTRN are forma generala:
EXTRN nume:tip, nume:tip,
in care tip precizeaza tipul simbolului. Acesta poate ti:
. BYTE, WORD, DWORD sau QWORD, in cazul in care simbolul este o variabila;
. NEAR sau FAR, in cazul in care simbolul este o eticheta sau un nume de procedura;
. ABS, in cazul in care simbolul este o constanta numerica simbolica. Sa consideram doua module de program, M1.ASM si M2.ASM:
; Modul M1.ASM
.model large
extrn var1:word, output:far
public var2
.data
var2 dw 7
.code
start:
mov ax, dgroup
mov ds, ax
add var1, 3
call output
end start
; Modul M2.ASM
.model large
public varl, output
extrn var2:word
.data
var 1 dw5
.code
output proc far
add var2, 1
retf
output endp
end
in acest exemplu, accesul la simbolurile globale este facilitat de faptul ca atat var1, cat si var2 sunt in acelasi segment de date, fiind accesibile prin registrul DS, initializat cu grupul de segmente DGROUP.
Daca nu am fi folosit directive simplificate, accesul la var1 si var2 ar fi fost mai complicat, deoarece nu s-ar fi cunoscut segmentul in care acestea sunt definite. In asemenea situatii, se foloseste operatorul SEG, care produce adresa de segment a simbolului:
mov ax, SEG var1
mov es, ax
add es:var1, 3
Directiva END
Aceasta directiva marcheaza sfarsitul logic al unui modul de program si e obligatorie in toate modulele. Tot ce se gaseste in fisierul sursa dupa aceasta directiva este ignorat la asamblare. Forma generala este:
END [punct_de_start]
in care punct_de_start este o eticheta sau un nume de procedura care marcheaza punctul in care se va da controlul dupa incarcarea programului in memorie. Intr-o aplicatie compusa din mai multe module si care se constituie intr-un program executabil, un singur modul trebuie sa aiba parametru in directiva END.
4 Contoare de locatii si directiva ORG
Contoarele de locatii controleaza procesul de asamblare, aratand la ce offset in cadrul segmentului curent se vor asambla instructiunea sau datele urmatoare. Un contor de locatii poate fi accesat explicit prin simbolul $.
La prima utilizare a unui nume de segment, contorul de locatii este initializat cu zero. Daca se revine intr-un segment care a mai fost utilizat, contorul de locatii revine la ultima valoare utilizata in cadrul acelui segment, ca in exemplul urmator:
.data ; $ = 0
db 5 dup(?)
.code
.data
db 7 ; $ = 5
Contoarele de locatii sunt utile la calculul automat al unor deplasamente sau dimensiuni. In exemplul urmator, se defineste un tablou de cuvinte TAB si o variabila LNG care contine numarul de cuvinte din tablou:
TAB dw 1, 2, 3, 4, 5, 6, 7, 8, 9
LNG dw ($ - TAB)/2
Expresia $ - TAB reprezinta numarul de octeti de la adresa TAB pana la adresa curenta. Impartind acest numar la 2, se deduce numarul de elemente din tablou. Putem acum adauga sau elimina date din tabloul TAB fara a actualiza lungimea LNG: asamblorul va calcula corect numarul de elemente din tablou.
Alte exemple de utilizare pot fi:
JMP $ ; Ciclu infinit: $ este chiar adresa
; instructiunii JMP
JMP $ + 5 ; salt relativ
Directiva ORG (Origin - Initializeaza contorul de locatii)
Aceasta directiva modifica explicit contorul de locatii curent, avand forma generala:
ORG expresie
De exemplu:
ORG $ + 5 ; Sare 5 octeti la asamblare
ORG 100H ; Asambleaza la offset-ul absolut 100H
Definirea si initializarea datelor
Asamblorul recunoaste trei categorii sintactice de baza:
. constante;
. variabile;
. etichete (inclusiv nume de proceduri).
Constantele pot fi absolute (numerice) sau simbolice. Constantele simbolice reprezinta nume generice asociate unor valori numerice. Variabilele identifica datele (un spatiu de memorie rezervat), iar etichetele identifica codul (program sau procedura).
Instructiuni de tipul MOV, ADD, AND etc. folosesc variabile si constante, iar instructiunile JMP si CALL folosesc etichete.
Variabilele si etichetele au asociate atribute, cum ar fi segmentul in care sunt definite, offset-ul la care sunt definite in interiorul segmentului etc.
1 Constante
Constantele numerice absolute pot ti:
. constante binare - se utilizeaza sufixul B sau b;
. constante octale - se utilizeaza sufixele O, Q, o sau q;
. constante zecimale - fara sufix sau cu sufixele D sau d;
. constante hexazecimale - se utilizeaza sufixele H sau h si prefixul 0 daca prima cifra este mai mare ca 9; pentru cifrele peste 9 se utilizeaza simbolurile AF sau af.
. constante ASCII - se scriu unul sau mai multe caractere ASCII intre semnul apostrof sau ghilimele;
lata exemple de constante absolute: 123, 123D, 10001100B, 177q, 0AAH, 3fh, 'a', 'AB'.
Constantele simbolice se definesc cu directiva EQU, in forma generala:
nume EQU expresie
De exemplu, liniile de program:
CR EQU 0DH
LF EQU 0AH
definesc constantele simbolice CR si LF, cu valorile 0DH si 0AH. Putem folosi aceste constante simbolice in orice context in care este permisa folosirea unei constante numerice.
Definirea si utilizarea variabilelor
Pentru definirea variabilelor, se utilizeaza directivele DB, DW, DD, DQ sau DT, care au fost introduse in Capitolul 1. Forma generala a unei definitii de date este:
nume directiva lista_de_valori
in care nume este identificatorul asociat definitiei respective, iar lista_de_valori este lista valorilor initiale, care poate cuprinde:
. constante numerice (absolute sau simbolice);
. simbolul ?
. o adresa, adica un nume de variabila sau de eticheta; se foloseste la DW si DD;
. un sirASCII;
. operatorul DUP (expresie), in care expresie poate fi:
. constanta numerica;
. lista de valori;
. simbolul ?
. operatorul DUP.
Semnificatia simbolului ? este locatie neinitializata, iar cea a operatorului DUP, repetarea de un numar de ori a expresiei din paranteza.
Sa consideram definitiile urmatoare:
var a db 2 dup (0, 3 dup (1))
var_ b db 1, 2, 3, ?, ?, ?
adr_ n dw var_a
adr_ f dd var_b
prima definitie este echivalenta cu:
var_a db 0, 1, 1, 1, 0, 1, 1, 1
Atributele datelor detinite sunt:
. segment - cel curent;
. offset - cel curent;
. tip - 1, 2, 4, 8, 10, dupa cum s-a utilizat ca directiva de baza DB, DW, DD, DQ sau DT.
Variabilele pot fi utilizate ca:
. variabile simple - var_a, var_b;
. variabile indexate - var_a [bx], var_b [2], ALFA [si][bx].
In cazul variabilelor indexate, trebuie tinut seama de tipul variabilei de baza. De exemplu, in urma definitiei tabloului:
B dw 10 dup(?)
expresiile indexate corecte din punct de vedere logic, care acceseaza elementele lui B, sunt B[0], B[2] etc. Din punct de vedere sintactic, putem scrie si:
mov ax, B[1]
dar aceasta forma va incarca in AL partea high a primului cuvant din tablou si in AH partea low a celui de-al doilea cuvant din tabloul B. Daca acest lucru s-a urmarit, perfect!
In cazul accesarii variabilelor prin expresii anonime, poate aparea necesitatea operatorului PTR. Instructiunile:
lea bx, B
inc byte ptr [bx][4]
inc word ptr [bx][4]
incrementeaza octetul, respectiv cuvantul de la adresa BX +
6 Definirea etichetelor. Directiva LABEL
Etichetele sunt folosite pentru specificarea punctelor tinta la instructiuni de salt sau apel sau pentru o specificare alternativa a datelor. In ambele cazuri, numele etichetei devine un nume simbolic asociat adresei curente de memorie. Atributele etichetelor sunt: segment, offset si tip. Pana acum am intalnit doua modalitati de definire a etichetelor:
. prin nume urmat de caracterul: - se defineste o eticheta de tip near;
. prin directiva PROC - numele procedurii este interpretat ca o eticheta cu tipul derivat din tipul procedurii;
O alta posibilitate este directiva LABEL, care are forma generala:
nume LABEL tip
Daca ceea ce urmeaza reprezinta instructiuni (cod), tipul etichetei va fi, de regula, NEAR sau FAR si eticheta va fi folosita ca punct tinta in instructiuni de timp JMP / CALL. Daca ceea ce urmeaza reprezinta definitii de date, tipul etichetei va fi, de regula, BYTE, WORD, DWORD etc.
Atributele NEAR sau FAR pot aparea numai daca eticheta este definita intr-un segment asociat cu registrul CS printr-o directiva ASSUME (explicita sau implicita).
Directiva LABEL este utila atunci cand dorim sa accesam variabile in moduri diferite. De exemplu, in urma definitiei:
ALFAW dw 1234H
o instructiune de forma inc ALFAB va incrementa octetul mai putin semnificativ al cuvantului, iar una de tip inc ALFAW va incrementa intreg cuvantul; un efect similar se poate obtine prin operatorul PTR.
Similar, definitia:
adr_proc label dword
proc_off dw ?
proc_seg dw ?
permite definirea explicita a segmentului si a offset-ului, dar si accesul la nivel de dublu-cuvant, de exemplu intr-o instructiune de apel indirect inter-segment
7 Definirea structurilor. Operatii specifice
Structurile reprezinta colectii de date (campuri sau membri) plasate succesiv in memorie, grupate sub un unic nume sintactic. Dimensiunea unei structuri este suma dimensiunilor campurilor componente. Forma generala a definitiei unei structuri este:
nume_structura STRUC
nume_membru definitie_date
nume structura ENDS
Prin aceasta se defineste tipul structurii (sablonul) fara a se rezerva spatiu de memorie. Definitiile de date pot cuprinde directive DB, DW etc. cu valori initiale asociate, ?, DUP etc., exact ca orice definitie de date. Numele membrilor structurii trebuie sa fie distincte, chiar daca apartin unor structuri distincte. lata un exemplu de definitie de tip de structura:
ALFA STRUC
a db ?
b dw 1111H
c dd 1234
d db ?
ALFA ENDS
O structura definita este interpretata ca un tip nou de date, care poate apoi participa la definitii concrete de date, cu rezervare de spatiu de memorie. De exemplu, putem defini o structura de tipul ALFA, cu numele x:
x ALFA <, , 777, 5>
in care ALFA este tipul de date, x este numele variabilei, iar intre paranteze unghiulare se trec valorile initiale ale campurilor structurii x. Prezenta virgulelor din lista de valori initiale precizeaza ca primii doi membri sunt initializati cu valorile implicite de la definitia tipului ALFA, al treilea membru este initializat cu valoarea 777, iar al patrulea cu valoarea 5. Astfel, definitia variabilei x este echivalenta cu secventa de definitii:
a db ?
b dw 1111H
c dd 777
d db 5
Principalul avantaj al structurilor este accesul la membri intr-o forma asemanatoare limbajelor de nivel inalt. De exemplu, pentru a incarca in SI campul b al structurii x, putem scrie:
mov si, x.b
Accesul la membrii structurii x poate fi deci detaliat in:
. x.a - variabila de tip byte
. x.b - variabila de tip word
. x.c - variabila de tip dword
. x.d - variabila de tip byte
Putem acum defini un tablou de 5 structuri de tip ALFA:
y ALFA 5 dup <, , , 10>
in care primii trei membri sunt initializati cu valorile de la definitia tipului structurii, iar al patrulea cu valoarea 10. Au acum sens expresii de forma: y[0].a, y[SI], y[8].c, y[BX].d etc. De fapt, toate aceste expresii se evalueaza din adresa de inceput a variabilei y la care se adauga un deplasament corespunzator. Expresia y[11].d este echivalenta cu y + 11 + deplasamentul campului d fata in cadrul tipului ALFA.
Se observa ca gestiunea deplasamentelor cade in sarcina utilizatorului. Daca dorim sa accesam campul c al celei de-a doua structuri din tabloul y, nu putem scrie y[1].c, asa cum am scrie intr-un limbaj de nivel inalt, ci y[8].c. Limbajul de asamblare ne pune la dispozitie operatorul TYPE, care intoarce numarul de octeti ocupat de o structura. Pentru a generaliza accesul la al i-lea element al tabloului y (i cuprins intre 0 si 4), putem scrie y[i*TYPE ALFA].c.
Problema se complica daca indicele i este cunoscut de-abia la momentul executiei (fiind memorat intr-un registru, de exemplu). O expresie de forma:
mov a1, y [SI*TYPE ALFA].d
are sens numai la procesoarele care accepta adresare cu factor de scala (80386 si peste) si numai daca factorul de scala este 1, 2, 4, sau 8. In caz contrar, deplasamentul trebuie calculat explicit prin operatii aritmetice.
Cu toate aceste limitari, structurile sunt intens utilizate atunci cand se lucreaza cu anumite sabloane fixe, cum ar fi, de exemplu, imaginea stivei la intrarea intr-o procedura sau transmiterea prin referinta a unei zone de date. Sa consideram o inregistrare logica descrisa prin campuri:
. campul NUME - sir ASCII de 30 de caractere
. campul PRENUME - sir ASCII de 20 de caractere
. campul COD - intreg pe 4 octeti
Dorim sa transmitem unei proceduri far cu numele PRELUCRARE o asemenea inregistrare. Cel mai simplu mod este de a transmite adresa (near sau far) a zonei de memorie in care este stocata inregistrarea, de exemplu printr-un registru sau o pereche de registre; pentru accesul comod la campuri definim structura:
PERSOANA STRUC
NUME db 30 dup (?)
PRENUME db 20 dup (?)
COD dd ?
PERSOANA ENDS
Definitia concreta a datelor si secventa de apel a procedurii este:
.data
om PERSOANA <'Ionescu', 'Ion', 77206>
adr_om dd om ; Pointer la om
.code
les di, adr_om
call PRELUCRARE
Se pune acum problema accesului la campurile inregistrarii, din interiorul procedurii. Beneficiem acum de structura PERSOANA. Ca sa incarcam adresa campului PRENUME vom scrie:
lea bx, es:[di].PRENUME
Perechea ES:DI contine adresa structurii om, iar expresia es:[di].PRENUME reprezinta deplasamentul campului PRENUME. In acest moment, in ES:BX avem adresa sirului de caractere de tip PRENUME. Similar se procedeaza si pentru celelalte campuri: ca sa preluam in DX:AX campul COD, putem scrie:
mov ax, word ptr es:[di].COD
mov dx, word ptr es:[di].COD + 2
Este evident ca toate secventele de mai sus se puteau inlocui cu deplasamente calculate explicit de catre programator. Incarcarea campului COD ar fi putut fi scrisa:
mov ax, word ptr es:[di + 50]
mov dx, word ptr es:[di + 52]
dar forma cu nume de campuri este mult mai clara si mai comoda. In plus, noi putem gresi la calculul unui deplasament, dar asamblorul nu.
Aceasta tehnica este benefica si din punctul de vedere al intretinerii unui program. Daca se modifica ulterior inregistrarea PERSOANA si se adauga inca un camp intre PRENUME si COD, toate deplasamentele calculate explicit trebuie modificate. In varianta cu structura, trebuie doar sa schimbam definitia structurii, restul fiind facut automat la asamblare.
8 Definirea inregistrarilor. Operatii specifice
Inregistrarile (RECORD) corespund de fapt unor structuri impachetate din limbajele de nivel inalt. Concret, o inregistrare este o definitie de campuri de biti de lungime maxima 8 sau 16. Din punct de vedere sintactic, definitia unei inregistrari este similara cu cea a unei structuri, forma generala fiind:
nume_inregistrare RECORD nume_camp:valoare,
sau, cu initializare implicita:
nume RECORD nume_camp:valoare = expresie,
Valorile care apar asociate cu numele de campuri dau de fapt numarul de biti pe care se memoreaza campul respectiv. In varianta cu initializare, expresia care apare dupa semnul egal se evalueaza la o cantitate care se reprezinta pe numarul de biti asociat campului respectiv. La fel ca la structuri, numele campurilor trebuie sa fie distincte, chiar daca apartin unor inregistrari diferite.
Sa consideram un exemplu:
Prin care se defineste un sablon de 16 biti, grupati in campurile X, Y si Z (vezi Figura 2)

Figura 2 Definitia unei inregistrari
La fel ca la structuri, putem acum defini variabile de tipul inregistrarii BETA:
VAL BETA <5, 2, 7>
in care valorile dintre parantezele unghiulare initializeaza cele trei campuri de biti. Se observa ca aceasta definitie este echivalenta cu definitia explicita:
VAL dw 0000101001000111B
Exista doi operatori specifici inregistrarilor: MASK si WIDTH. Operatorul MASK primeste un nume de camp si furnizeaza o masca cu bitii 1 pe pozitia campului respectiv si 0 in rest. Astfel, expresiile MASK X si MASK Y sunt echivalente cu constantele binare 1111111000000000B si 0000000111100000B.
Asemenea expresii pot fi utilizate pentru selectarea campurilor respective, ca in exemplele de mai jos:
AND AX, MASK Y ; Filtreaza campul Y
AND BX, NOT MASK Z ; Forteaza campul Z la 0
Operatorul WIDTH primeste un nume de inregistrare sau un nume de camp dintr-o inregistrare, intorcand numarul de biti ai inregistrarii sau ai campului respectiv. De exemplu, secventa:
MOV AL, WIDTH BETA ; AL <--- 16
MOV BL, WIDTH Y ; BL <--- 4
va incarca in AL valoarea 16 si in BL valoarea
Daca se utilizeaza un nume de camp intr-o instructiune de tip MOV, se va incarca un contor de deplasare, util pentru a deplasa campul respectiv pe pozitiile cele mai putin semnificative.
Sa presupunem ca dorim sa testam valoarea numerica a campului Y din inregistrarea VAL. Nu este suficient sa-l izolam si sa folosim o instructiune de comparatie. Inainte de comparatie, campul Y trebuie adus pe pozitiile cele mai din dreapta. Realizam aceste operatii prin secventa:
AND AX, MASK Y ; Selectare camp Y
MOV CL, WIDTH Y ; Incarcare in CL a valorii 4
SHR AX, CL ; Deplasare camp Y la dreapta
9 Operatori in limbajul de asamblare
Limbajul de asamblare dispune de un set de operatori cu care se pot forma expresii aritmetice si logice. Aceste expresii sunt evaluate la momentul asamblarii, producand, de fapt, constante numerice. Este esential sa deosebim instructiunile executabile (codul masina) de operatiile care se fac la momentul asamblarii.
9.1 Operatori aritmetici si logici
Operatorii aritmetici sunt: +, -, *, /, MOD, SHL si SHR. Primii patru au semnificatii evidente si opereaza numai cu cantitati intregi. Operatorul MOD produce restul la impartire, iar SHL si SHR provoaca deplasare la stanga sau la dreapta.
De exemplu, instructiunea:
mov ax, 1 SHL 3 ; 1 deplasat la stanga cu 3 biti
este echivalenta cu:
mov ax, 100B
Similar, in directiva:
COUNT dw ($ - TAB)/2
se va evalua la momentul asamblarii expresia ($- TAB)/2, adica diferenta dintre contorul curent de locatii si adresa TAB, impartita la 2.
Operatorii logici sunt NOT, AND, OR si XOR, cu semnificatii evidente. Toti acesti operatori accepta drept operanzi constante intregi; operatiile respective se fac la nivel de bit. Ei nu trebuie confundati cu instructiunile executabile cu acelasi nume. In instructiunea:
and al, (1 SHL 3 ) OR (1 SHL 5)
registrul AL va fi incarcat cu constanta 101000B.
9.2 Operatori relationali
Operatorii relationali sunt EQ, NE, LT, LE, GT, GE, cu semnificatii evidente. Acestia intorc valori logice, codificate ca 0 sau ca secvente de 1 pe un numar corespunzator de biti. in urma definitiilor:
x db 1 EQ 2
y dw 1 NE 2
z dd 1 LT 2
variabilele x, y si z vor fi initializate cu constantele 0, 0FFFFH, respectiv 0FFFFFFFFH.
Operatorii relationali sunt utilizati in special in directivele de asamblare conditionata.
9.3 Operatorul de atribuire =
Operatorul de atribuire = defineste constante simbolice, fiind similar cu directiva EQU, dar permite redefinirea simbolurilor utilizate. O definire de forma:
N EQU 1
N EQU 2
este semnalata ca eroare, dar secventa:
N = 1
este corecta.
Acest operator este utilizat in special in definitiile de macroinstructiuni.
9.4 Operatori care intorc valori
Acesti operatori se aplica unor entitati ale programului in limbaj de asamblare (variabile, etichete), intorcand valori asociate acestora.
. Operatorul SEG
Se aplica atat variabilelor, cat si etichetelor si furnizeaza adresa de segment asociata variabilei respective. Daca var este o variabila, atunci putem scrie secventa:
mov ax, SEG var
mov ds, ax
. Operatorul OFFSET
Este similar cu SEG, furnizand offset-ul asociat variabilei sau etichetei:
mov bx, OFFSET var
. Operatorul THIS
Acest operator creeaza un operand care are asociate o adresa de segment si un offset identice cu contorul curent de locatii. Forma generala a operandului este:
in care tip poate fi BYTE, WORD, DWORD, QWORD sau TBYTE pentru definitii de date, respectiv NEAR sau FAR pentru etichete. Operatorul THIS se utilizeaza de obicei cu directiva EQU. De exemplu, definitia constantei simbolice:
ALFA EQU THIS WORD
este echivalenta cu definitia unei etichete:
ALFA LABEL WORD
. Operatorul TYPE
Se aplica variabilelor si etichetelor, intorcand tipul acestora. Pentru variabile intoarce valorile 1, 2, 4, 8 sau 10 pentru variabile simple (definite cu directivele DB, DW, DD, DQ respectiv DT), iar pentru structuri intoarce numarul de octeti pe care este memorata structura respectiva. Pentru etichete, intoarce tipul etichetei (NEAR sau FAR).
. Operatorul LENGTH
Se aplica numai variabilelor si intoarce numarul de elemente definite in variabila respectiva. De exemplu, in definitia:
A DW 100 dup (?)
expresia LENGTH A are valoarea 100.
. Operatorul SIZE
Se aplica numai variabilelor si intoarce dimensiunea in octeti a variabilei respective. In definitia de mai sus, expresia SIZE A are valoarea 200.
Pentru o variabila oarecare var, are loc totdeauna identitatea:
SIZE var = (LENGTH var) * (TYPE var)
Acesti operatori sunt utili la prelucrarea tablourilor. Secventa urmatoare nu depinde de tipul de baza al tabloului TAB si nici de dimensiunea sa:
.data
TAB dd 100 dup (?)
.code
mov cx, LENGTH TAB
lea si, TAB
bucla:
add si, TYPE TAB
loop bucla
Daca inlocuim acum tipul de baza al tabloului TAB cu o structura de tip PERSOANA (definita in 7), modificand si dimensiunea:
PERSOANA STRUC
. . . . .
PERSOANA ENDS
.data
TAB PERSOAMA 50 dup <,,,>
partea de program nu trebuie modificata, deoarece asamblorul va evalua corect expresiile LENGTH TAB si TYPE TAB.
9.5 Operatorul PTR
Acest operator se aplica atat variabilelor, cat si etichetelor, avand ca efect schimbarea tipului variabilei sau al etichetei respective. Este obligatoriu in cazul in care se folosesc referinte anonime la memorie, din care nu se poate deduce tipul operandului:
add word ptr [bx], 2
call dword ptr [bx]
call near ptr proc
10 Directive de asamblare conditionata
Permit ignorarea unor portiuni din textul sursa, functie de o conditie care se poate evalua la asamblare. Directiva de baza este IF, cu forma generala:
IF expresia
[ELSE]
ENDIF
Daca expresia din directiva IF este adevarata (adica este diferita de 0), se asambleaza portiunea de program dintre IF si ELSE si se ignora portiunea dintre ELSE si ENDIF. Daca expresia din IF este falsa, se asambleaza portiunea de program dintre ELSE si ENDIF si se ignora portiunea dintre IF si ELSE. Ramura ELSE este optionala.
Aceste operatii se petrec la momentul asamblarii, permitand intretinerea comoda a unui program de dimensiuni mari sau chiar mentinerea in acelasi text sursa a mai multor variante de program executabil. Sa presupunem ca dorim un program care sa poata fi configurat rapid pentru modele de date "mici', respectiv "mari'. Aceasta presupune ca orice secventa de instructiuni care defineste, citeste sau scrie o adresa sa fie inclusa in directive de asamblare conditionata:
FALSE equ 0
TRUE equ NOT FALSE
DATE_MARI equ TRUE
DATE_MICI equ NOT DATE_MARI
.data
X dw 100 dup (?)
IF DATE_MARI
ADR_X dd X
ELSE
ADR_X dw X
ENDIF
.code
IF DATE_MARI
lds si, ADR_X
ELSE
mov si, ADR_X
ENDIF
; Prelucrare TABLOU
Exista si directivele IFDEF / ENDIF si IFNDEF / ENDIF, care testeaza daca un simbol este definit sau nu, si directivele IFB / ENDIF (If Blank), respectiv IFNB / ENDIF (If Not Blank), care testeaza daca un simbol este vid sau nevid. Acestea din urma vor fi utilizate la definirea macroinstructiunilor.
In expresiile care apar in directivele de tip IF se utilizeaza de obicei operatori logici si relationali.
Sa consideram un exemplu de program sursa multifunctional. Se doreste scrierea unei secvente care sa calculeze in acumulator suma elementelor unui tablou A (de octeti sau de cuvinte), definit in segmentul curent de date, ca suma pe octeti si pe cuvinte, indiferent de tipul si de dimensiunea tabloului. Tipul sumei este dictat de constantele simbolice SUM_B si SUM_W.
FALSE equ 0
TRUE equ NOT FALSE
SUM_B equ TRUE
SUM_W egu NOT SUM_B
.code
if SUM_B
mov cx, SIZE A ; Numar de iteratii
else
mov cx, (SIZE A)/2
endif
xor bx, bx ; Indice initial
mov ax, bx ; Suma initiala
bucla:
if SUM_B
add al, byte ptr A [bx] ; Suma pe octet
inc bx ; Actualizare adresa
else
add ax, word ptr A [bx] ; Suma pe cuvant
inc bx ; Actualizare adresa
inc bx
endif
loop bucla ; Bucla
if SUM_W AND (TYPE A EQ 1) AND ((SIZE A) MOD 2) EQ 1
push ax
mov al, byte ptr A [bx] ; Un eventual
cbw ; ultim
mov dx, ax ; octet
pop ax
add ax, dx
endif
Se observa ca nu putem initializa contorul CX cu expresia LENGTH A, deoarece numarul de iteratii este dictat de modul de calcul al sumei, si nu de tipul tabloului. Ca atare, luam dimensiunea in octeti a tabloului, pe care o impartim la 2 in cazul sumei pe cuvant. Calculul sumei si actualizarea adresei sunt evidente.
Apare o problema speciala in urmatoarea situatie: se cere suma pe cuvant, iar tabloul, definit ca tablou de octeti, are un numar impar de elemente. In aceasta situatie, este evident ca ultimul octet nu este considerat in bucla de sumare. Ca atare, el este adaugat explicit la sfarsit.
De remarcat formularea situatiei de mai sus in termenii conditiei logice de la ultima directiva IF:
. SUM_W codifica cererea de calcul a sumei la nivel de cuvant;
. (TYPE A EQ 1) codifica situatia in care tabloul A este definit la nivel de octet;
. ((SIZE A) MOD 2) codifica situatia in care tabloul are un numar impar de octeti.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2235
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2026 . All rights reserved