| CATEGORII DOCUMENTE |
| Animale | Arta cultura | Divertisment | Film | Jurnalism | Muzica |
| Pescuit | Pictura | Versuri |
Prezentarea procesorului β
-banda de asamblare cu 5 etaje-
Cuprins:
1. Prezentarea semnalelor de la intrarile multiplexoarelor plasate in diversele sectiuni ale benzii de asamblare
2. Prezentarea semnalelor de comanda ale resurselor hardware din diversele sectiuni ale benzii de asamblare
3. Descrierea operarii procesorului , pentru implementarea tuturor categoriilor de instructiuni.
4. Traducerea in romana a textului din anexa, care cuprinde probleme referitoare la banda de asamblare, pentru procesorul
5. Bibliografie
SUBIECTUL I
Prezentarea semnalelor de la intrarile multiplexoarelor
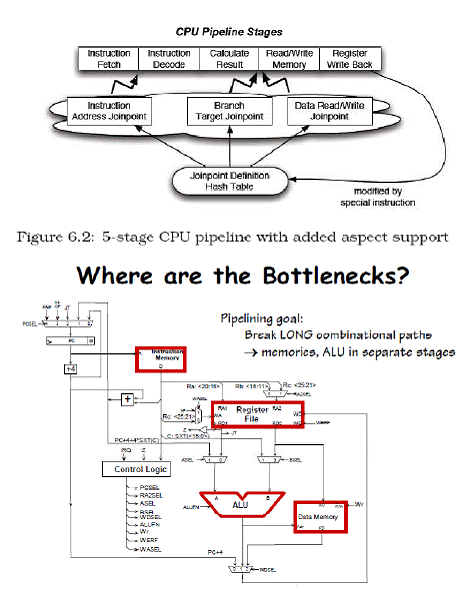
Schema procesorului β cu 5 etaje de asamblare este:
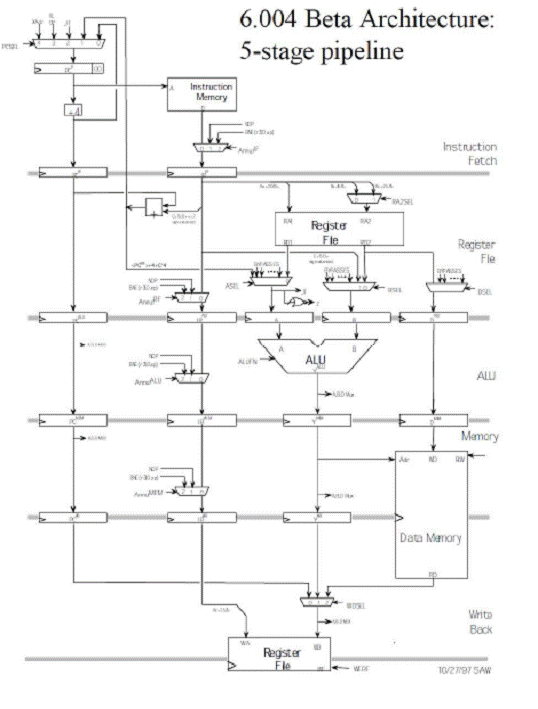
Semnalele de la intrarile multiplexoarelor:
Nivelul IF :
Multiplexorul pentru det. PC :
XAdr -> adresa pentru tipuri de exceptii
ILL Op -> adresa in cazul unei exceptii (cauzate de o eroare de cod al operatiei)
JT -> adresa instructiunii de salt
1 -> adresa instructiunii BNE (PC+4+4*SXT(C ))
0 -> adresa PC+4
Multiplexorul pentru selectie instructiune:
0 -> instructiunea det de Instruction Memory
1 -> NOP
2 -> instructiunea care nu e corecta va fi inlocuita cu BNE (R31, 0, XP)
Nivelul RF:
Multiplexorul pentru det. valorii A, avand intrarile :
PC+4+4*SXT(C)
Valoarea furnizata de multiplexorul A BYPASS
Multiplexorul pentru det. valorii B, avand intrarile :
PC+4+4*SXT(C)
Valoarea furnizata de multiplexorul B BYPASS
Multiplexorul pentru selectie instructiune, avand aceleasi intrari ca si multiplexorul similar de la nivelul IF.
2 multiplexoare BYPASSES
La nivelurile ALU si Memory se observa existenta multiplexoarelor pentru selectia instructiunii, avand drept intrari:
NOP
BNE(R31, 0, XP)
IR de la nivelul RF (respectiv ALU)
Nivelul WB :
Multiplexor pentru selectarea datelor de iesire. Intrarile in acest caz sunt :
Datele furnizate de ALU
PCMem
Datele furnizate de Data Memory
Subeictul II.
Semnale de comanda ale resurselor hardware :

Nivelul IF :
Nivelul ALU :
Nivelul M :
Nivelul WB :
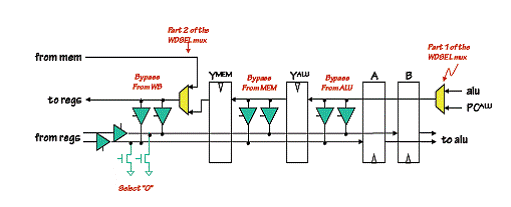
Pentru a reduce numarul ocolirilor logice, multiplexorul WDSEL a fost scindat: alegerea intre ALU si PC+4 este facuta la nivelul ALU, in timp ce alegerea intre ALU/PC si MEMDATA este facuta la nivelul WB.
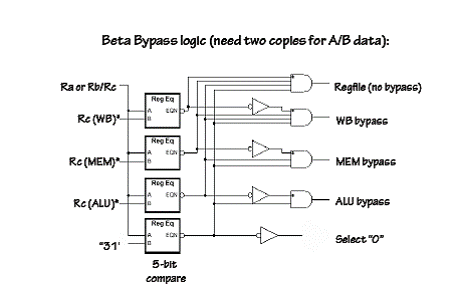
Caile de ocolire :
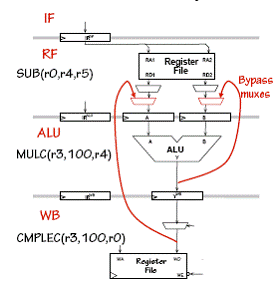
Se adauga cai speciale, numite BYPASSES (ocoliri), care dirijeaza rezultatele de la nivelul ALU si WB la nivelul RF.
Subiectul III
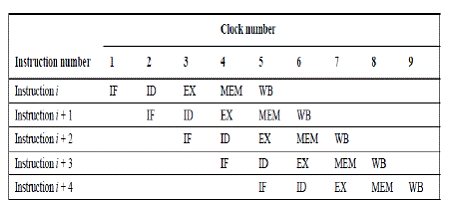
Fiecare instructiune poate fi pusa in aplicare in cel mult cinci cicluri de ceas. Cele cinci
cicluri de ceas sunt dupa cum urmeaza.
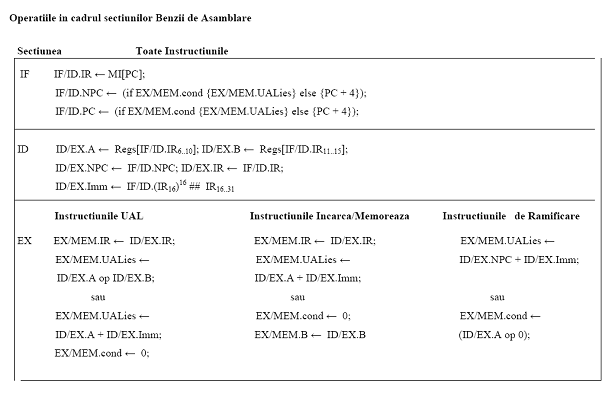
1. Instruction fetch stage (IF):
Trimite contorul programului (PC) pentru a descarca si aduce instructiunea curenta din
memorie. Actualizeaza PC prin adaugarea de patru octeti la PC.
2. Instruction decode/register fetch cycle (RF/ID):
Decodeaza instructiunea citind registrele corespunzatoare registrului sursa din registru
dosar. Executa testul de egalitate cu privire la registre in momentul citirii pentru o posibila legatura intre ele.
3. Execution/effective address cycle (EX/ALU):
ALU functioneaza cu operanzii pregatiti in ciclul anterior, efectuand una dintre cele trei
functii in functie de tipul de instruire:
a) memorie de referinta:
ALU adauga registrul de baza si de offset, pentru a forma adresa efectiva.
b) Inregistreaza Inregistreaza instructiune ALU:
ALU efectueaza operatiunea specificata de codul de operatie ALU bazandu-se pe
valorile citite din registru dosar.
c) Inregistreaza Imediat instructiune ALU :
ALU efectueaza operatiunea specificata de codul de operatie ALU bazandu-se pe prima
valoare citita din registru dosar si pe semnul operatiei.
4. Memory Access (MEM):
Daca instructiunea este o citire, atunci citeste din memorie, folosind adresa efectiva
calculata in ciclul precedent. Daca este o scriere, atunci data de la cel de-al doilea registru citit din registru este scrisa in memorie, folosind in mod adresa efectiva.
5. Write-back ciclu (BM):
Inregistreaza Inregistreaza Instructiune ALU instructiuni sau instructiune de citire:
Scrie rezultatul in registtru, indiferent daca este vorba de memorie de sistem (pentru o
citire) sau de la ALU (pentru o instruire ALU).
In prima figura de mai jos este prezentata o schema simpla de pipelining.
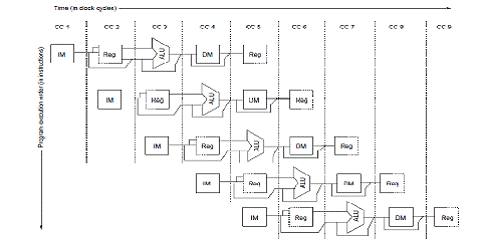
In figura urmatoare este prezentat un pipeline care poate fi gandit ca o serie de
cai de date mutate in timp. Acest lucru arata suprapunerea intre parti ale cailor de date,
cu ciclu de ceas 5 (CC 5) care indica starea de echilibru. Pentru ca registrul de fisiere
este folosit ca o sursa in etapa de identificare si ca o destinatie in etapa BM, apare de
doua ori. Se arata ca este citit intr-o singura etapa si scris in alta utilizand o linie
solida, pe dreapta sau la stanga, respectiv, si o linie intrerupta, pe de alta parte.
Abrevierea IM este utilizat pentru instruire de memorie, DM de date, memorie, si CC
pentru ciclu de ceas.

Subiectul IV
Problema 1:
A. In cadrul procesorului Beta, avand o structura de banda de asamblare cu 5 etaje, cand este utilizata abilitatea hardware de a insera NOP in fluxul de instructiuni la nivelul IF? (folosind MUX,controlat de catre AnnulIF
NOP este inserat la nivelul IF cand instructiunile sunt anulate in ramificatia de intarziere din cauza unei ramificatii deja luate sau cand se goleste banda de asamblare din cauza unei erori la nivelul ALU sau MEM.
B. In cadrul procesorului Beta, avand o structura de banda de asamblare cu 5 etaje, cand este utilizata abilitatea hardware de a insera NOP in fluxul de instructiuni la nivelul ALU? (folosind MUX,controlat de catre AnnulALU
Daca are loc o eroare la nivelul MEM (ex: accesare ilegala a memoriei) , instructiunea curenta din stadiul ALU trebuie inlaturata, ceea ce hardware-ul face substituind NOP. De retinut este faptul ca o eroare la nivelul MEM inlatura toate instructiunile curente din IF, RF si ALU deoarece acestea se afla din punct de vedere logic dupa instructiunea ce a cauzat eroarea.
C. Ben Bitdiddle se gandeste sa modifice un procesor Beta cu banda de asamblare cu 5 etaje prin adaugarea unei instructiuni "Salt daca Memorie Zero" (JMZ) care aduce continutul unei locatii de memorie si executa un salt daca memoria este nula. Cate intarzieri in cadrul ramificartiei ar urma o instructiune JMZ in cazul procesorului Beta cu banda de asamblare cu 5 etaje, modificat?
Continutul locatiilor de memorie accesate de instructiunea JMZ nu sunt disponibile pana ce nu se ajunge la stadiul WB. Daca decizia de ramificare este efectuata in acel punct, instructiunile din MEM, ALU, IF SI RF au fost deja aduse, ceea ce inseamna ca sunt 4 intarzieri.
D. Sa presupunem ca urmatorul cod ruleaza pe un procesor Beta cu banda de asamblare cu 5 etaje, cu ocolire si o ramificatie de intarziere cu anulare.
PUSH (R1)
PUSH (R2)
LD (BP, -12, R0)
LD (BP, -16, R1)
CMPEQ (R0, R1, R2)
BT (R2, L1)
Cand CMPLEC este executat, presupunand ca nu exista intreruperi, de unde provine valoarea pentru R0? Dar valoarea pentru R1? (Alegerile ar fi: din registre sau prin ocolire din unul din stadiile benzii de asamblare).
Instructiunea CMPLEC intarzie in stadiul RF pana ce valorile pentru R0 SI R1 sunt disponibile. Valoarea pentru R1 nu este disponibila pana cand cel de-al doilea LD ajunge in stadiul RB, moment in care rezultatele de la primul LD au fost deja scrise in registru. Asadar, valoarea lui R0 provine din registru, iar valoarea lui R1 este obtinuta prin ocolire din stadiul WB.
E. Care din urmatoarele hazarde ale benzii de asamblare nu pot fi rezolvate prin transparenta si la nici un cost de performanta prin ocolire?
A. Un registru distribuit intre instructiuni ALU consecutive.
B. BR urmat de o instructiune ALU folosind BR.
C. LD urmat de o instructiune ALU folosind LD.
D. Acces la LP de catre prima instructiune intr-o procedura apelata.
E. Acces la XP de catre prima instructiune intr-o rutina de tratare de intrerupere.
(C) Atat timp cat datele dintr-o instructiune LD nu sunt disponibile pana in stadiul WB, ocolirea nu ajuta.
F. Numarul de ramificatii de intarziere ilustreaza:
A . Distanta dintre stadiul de aducere a instructiunii si stadiul la care este luata decizia de ramificare.
B. Distanta dintre stadiul de writeback si stadiul la care este luata decizia de ramificare.
C. Lungimea totala a benzii de asamblare.
D. Pozitia la nivelul benzii de asamblare a stadiului de aducere a instructiunilor.
E. Numarul de cicluri necesar pentru aducerea din memoria de date.
(A) Numarul de ramificatii de intarziere se refera la numarul de instructiuni ce urmeaza o ramificatie, care sunt aduse de catre banda de asamblare inainte sa fie luata decizia de ramificare.
Problema 2:
O metoda comuna pentru comunicarea intre dispozitivele de I/O este asocierea lor cu una sau mai multe adrese de memorie. Aceasta tehnica poarta numele de maparea memoriei de I/O. Unele locatii I/O sunt utilizate pentru adresarea de stari care indica disponibilitatea unui dispozitiv I/O asociat. Aceste stari identifica daca un dispozitiv de intrare are date noi de intrare sau un dispozitiv de iesire a procesat iesirea anterioara. Deseori, computerele vor cicla asteptand starea dispozitivelor de I/O. Sa consideram urmatoarea secventa de instructiuni pentru verificarea starii unui dispozitiv extern de I/O.
loop: LD(R31, status, R0)
BEQ(R0, loop, R31)
ADD (R0, R1, R2)
Urmatoarea diagrama ilustreaza executia acestei secvente de instructiuni pe un procesor Beta cu banda de asamblare cu 5 etaje:
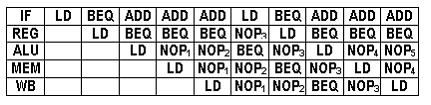
A. Cate cicluri de ceas sunt necesare pentru executia unei iteratii a buclei (cu 2 instructiuni) date?
5 cicluri. Masurand de la instructiunea LD a unei iteratii pana la instructiunea LD a urmatoarei iteratii, obtinem 5 cicluri.
B. Ce aspect al secventei de instructiuni determina inserarea NOP1 in banda de asamblare?
Campul RA al lui BEQ asociaza campul RC al lui RD in cadrul stadiului ALU. BEQ testeaza valoarea in R0, care reprezinta destinatia instructiunii precedente LD. Memoria de date accesata de LD nu va fi disponibila procesorului Beta pana ce LD nu va ajunge in stadiul WB. Asadar, instructiunea LD avanseaza in cadrul benzii de asamblare, in timp ce instructiunea BEQ este intarziata in stadiul RF pana ce sunt date disponibile. "Distanta" ce apare intre cele 2 instructiuni este umpluta cu NOP-uri (in acest caz, de NOP1 si de NOP2).
C. Ce aspect al secventei de instructiuni determina inserarea NOP2 in banda de asamblare?
Campul RA al lui BEQ asociaza campul RC al lui LD in cadrul stadiului MEM.
D. Ce aspect al secventei de instructiuni determina inserarea NOP3 in banda de asamblare?
Toate instructiunile BEQ determina inserarea NOP-urilor. S-a decis anularea instructiunilor care urmeaza dupa ramificatii deja parcurse. Acest lucru este realizat la nivelul IF prin inlocuirea instructiunilor anulate cu NOP-uri.
E. Intr-o versiune non-standard a procesorului Beta cu 5 benzi de asamblare, unde instructiunea ce urmeaza unei ramificatii nu se anuleaza, care dintre urmatoarele afirmatii este adevarata:
A. Instructiunea ADD este executata de fiecare data in timpul buclei.
B. Bucla va dura tot 5 cicluri de ceas.
C. Valoarea registrului R0, testata de instructiunea BEQ provine dintr-o cale de ocolire.
D. Valoarea registrului R0, accesata de instructiunea ADD provine din fisierul-registru.
Toate afirmatiile sunt adevarate.
Problema 3:
Procesorul Beta cu 5 benzi de asamblare executa urmatoarea secventa:
ADD(R31, R31, R31) |NOP
ADD(R1, R2, R1)
LD(R1, 4, R1)
SUB(R1, R5, R6)
ORC(R1, 123, R1)
SHL(R1, R1, R1)
A. Ce intrare este selectata de catre ocolirea RA MUX cand ADD se afla
La nivelul ALU?
Intrarea ALU. Instructiunea LD este in stadiul RF si trebuie sa ia rezultatul instructiunii ADD.
B Ce intrare este selectata de catre ocolirea RA MUX cand LD se afla
in stadiul WB?
Intrarea WD la fisierul-registru. Dupa numeroase intarzieri (SUB este mentinut in stadiul RF) iesirea lui LD este ocolita inapoi in stadiul RF.
Problema 4:
Fiecare din urmatoarele scenarii ilustreaza o captura a unui procesor Beta cu 5 benzi de asamblare ce executa o secventa de cod. Pentru fiecare scenariu, indicati setarile corespunzatoare pentru MUX de ocolire, IR MUXes si registrii IR/ALU. Apoi realizati o captura aratand starea procesorului Beta cu 5 benzi de asamblare in timpul ciclului urmator.

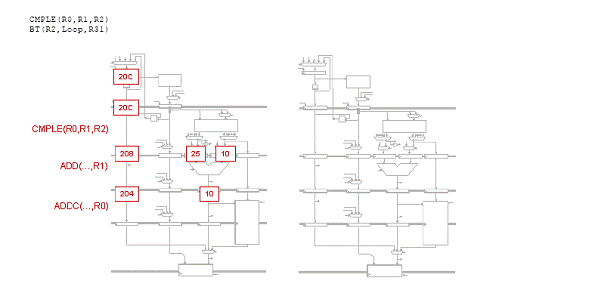
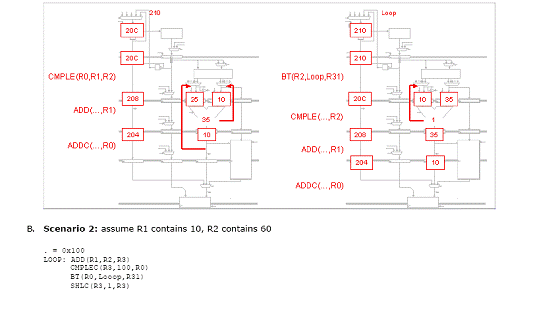
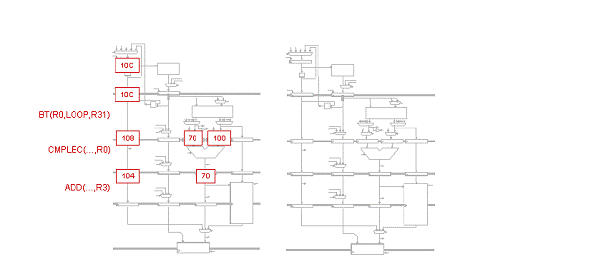


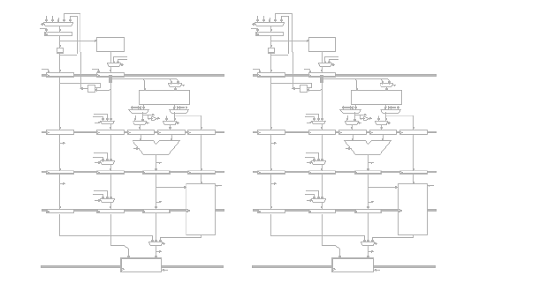
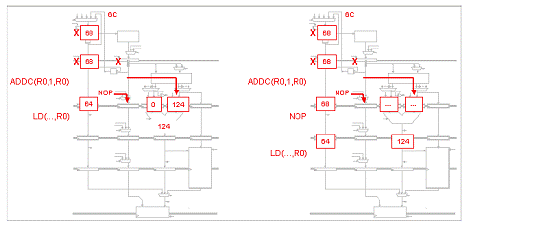
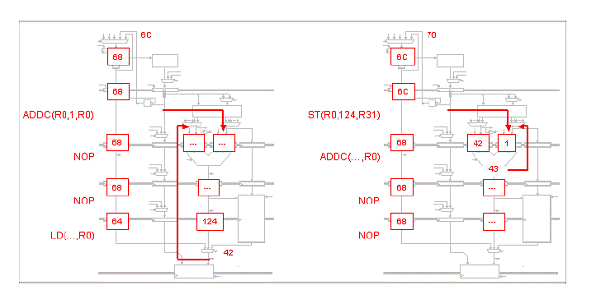
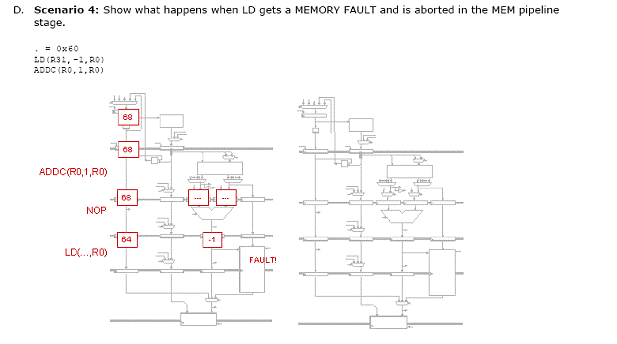
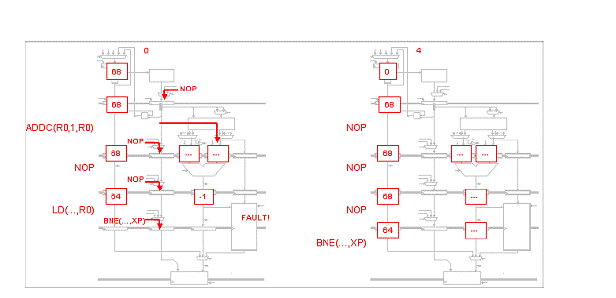
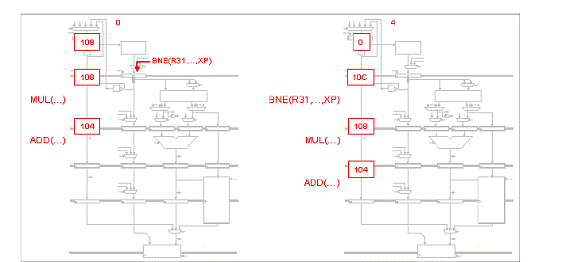
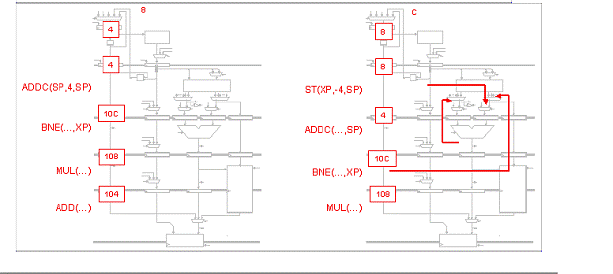
Problema5:
Sa consideram executia urmatoarei seccente de cod, pe un procesor Beta cu 5 benzi de asamblare:
ADDC(R31, 3, R0)
SUBC(R0, 1, R1)
MUL(R0, R1, R2)
XOR(R0, R2, R3)
ST(R3, Ox1000, R31)
A. Ce valoare este stocata in locatia 0x1000?

B. In ce moment pe parcursul executiei secventei de cod de mai sus are loc ocolirea din stadiul de Memorie pana la multiplexoarele de intrare ASEL sau BSEL?
Cand MUL este in stadiul RF.
C. Urmatoarea secventa de cod este executata pe un procesor Beta cu defecte, a carui singura problema este ca datele ocolite din stadiul WB sosesc la MUX ASEL si BSEL ca fiind nule. Ce valoare este memorata in locatia 0x1000 utilizand acest procesor cu defecte?

D Acum aceeasi secventa de cod este executata pe un alt procesor Beta cu defecte. In acest caz, datele citite din fisierul-regirstru de pe orice port sunt zero. Ce valoare va scrie secventa de mai sus in locatia de memorie 0x1000 utilizand acest procesor?
5! Dupa cum s-a mentionat in raspunsul de la A, nu se face nici un acces la fisierul-registru cand sunt aduse continuturile registrelor, caile ocolitoare fiind mereu utilizate.
Problema 6:
Penny Pincher, agent de achizitii la Flaky Beta's Inc., a cumparat numeroase procesoare Beta cu 5 benzi de asamblare si ocolire intreaga si o ramificatie de intarziere (FB3). Aceste procesoare au un singur defect: legatura dintre dispozitivele de intrare ale PC-ului la WDSEL MUX este defectuoasa. Penny este mandra de achizitia facuta, dar membrii echipei software FBI atentioneaza ca apeluri de procedura nu functioneaza din cauza ca scrierea in registrul LP utilizeaza legatura defectuoasa.
Dupa ce s-a gandit un moment, Penny propune un apel al unei proceduri apropiate f, in locul generarii BR.
LDR(.+8, LP)
BR(f, r31)
LONG(.+4)
A. Care din urmatoarele afirmatii descrie cel mai bine schema lui Penny?
A. Functioneaza
B. Functioneaza numai daca secventa returnata din procedura este modificata a.i. se adauga 4 la valoarea lui LP inainte de executia lui JMP(LP)
C. Nu functioneaza deoarece si LDR este defectuoasa din cauza erorilor din calea FB3
D. Functioneaza numai daca programul este plasat in ultimele 32767 cuvinte din memoria principala
E. Nu functioneaza
(A) LDR incarca adresa instructiunii ce urmeaza dupa LONG(), deci cand procedura executa return se revine la punctul corect.
B. Indiferent daca schema lui Penny functioneaza sau nu, echipa software doreste o alta solutie. Penny isi aminteste ca toate caile ocolitoare in arhitectura procesorului Beta sunt functionale, cu exceptia celei de la final (stadiul de writeback).
Intr-un apel de procedura, in timpul ciclului in care prima instructiune a procedurii apelate este in stadiul RF, unde este adresa de revenire, in cadrul procesorului Beta cu banda de asamblare cu 5 etaje?
In memoria benzii de asamblare. Secventa de instructiuni este BR, instructiune anulata, prima instructiune a procedurii, i.e., BR este cu 2 stadii mai departe in banda de asamblare.
C. Presupunand ca toate procedurile sunt compilate avand o intrare standard si o secventa de cod de iesire, si ca nu trebuie sa ne facem probleme din cauza intreruperilo, o ajuta pe Penny faptul ca ocolirile inca functioneaza sa gaseasca o noua solutie?
Da! Insa secventa de intrare va trebui modificata prin adaugarea ADDC(LP,0,LP) drept prima instructiune pentru a nu-si pierde valoarea din cauza defectului lui FB3. Adaugand aceasta instructiune, are loc ocolirea valorii lui LP din stadiul M, exact inainte de a nu fi modificata de partea cu erori.
Problema 7
Pipelines-R-Us, o firma situata in Valley ce se ocupa cu arhitectura procesoarelor, a trimis urmatoarea propunere catre echipa 6.004. Ei au observat ca stadiul MEMORIEI al procesorului Beta cu banda de asamblare cu 5 etaje nu este folosit decat in cadrul operatiilor de incarcare si stocare. Ei propun omiterea definitiva a acestui stadiu atunci cand memoria nu este folosita, asa cum este ilustrat in urmatorul tabel in care se arata cum o instructiune circula prin stadiile benzii de asamblare in cicluri succesive:

P-R-U mentioneaza ca astfel instructiunile ce parasesc stadiul MEM pot termina mai repede un ciclu si deci majoritatea programelor vor rula cu 20% mai repede!
In vederea acordarii de raspunsuri la intrebarile de mai jos, se presupune ca atat implementarea originala, cat si cea P-R-U sunt complet ocolitoare.
A. Explicati, pe scurt, de ce scaderea latentei unei singure instructiuni nu are neaparat un impact asupra executiei procesorului. Indicatie: luati in calcul timpul necesar procesorului Beta original pentru a executa o secventa de 1000 de ADD-uri. Apoi comparati acel timp cu timpul necesar procesorului Beta modificat sa execute aceeasi secventa.
Procesorul Beta initial are nevoie de 5 perioade de ceas (T) pentru a
executa primul ADD, si apoi de inca 999T pentru a executa restul. Deci timpul total pentru a procesa 1000ADD-uri este 1004T. In cazul procesorului Beta modificat va fi nevoie de 4 perioade de ceas (T) pentru a executa primul ADD, si de inca 999T pentru a executa restul. Deci timpul total pentru procesarea a 1000ADD-uri este 1003T, ceea ce nu este o imbunatatire semnificativa comparativ cu procesorul Beta nemodificat.
B. Sa consideram o secventa de instructiuni LD si ADD alternante. Presupunand ca instructiunile LD utilizeaza diferite registre sursa si destinatie in comparatie cu instructiunile ADD (i.e. nu sunt introduse intarzieri datorita dependentelor intre date), care este rata de executie a instructiunilor pentru procesorul Beta nemodificat?
Fara intarzieri, un procesor Beta nemodificat executa instructiunile alternante LD si ADD cate una pe perioada de ceas.
C. Acum aratati cum aceeasi secventa de instructiuni se va executa pe un procesor modificat asa cum P-R-U sugereaza. Presupunem ca suportul hardware va intarzia o instructiune ce necesita un stadiu al benzii de asamblare ce este deja utilizat de o instructiune anterioara. De exemplu, daca doua instructiuni doresc sa foloseasca stadiul WB in acelasi ciclu, instructiunea ce a inceput mai tarziu este fortata sa astepte un ciclu. Desenati o banda de asamblare si aratati unde anume trebuie introduse intarzieri pentru a evita conflictele.
Daca o instructiune ce utilizeaza toate stadiile (de ex LD/ST etc) este executata inaintea unei instructiuni ce utilizeaza numai 4 stadii (de ex. ADD/SUB etc) atunci cea de-a doua trebuie intarziata deoarece stadiul WB este utilizat deja si nu poate fi folosit de 2 instructiuni in acelasi timp. Ex:
foo: LONG( 0 )
LD(foo,R0)
ADD( R1, R2, R3)
Pentru o executie corecta, banda de asamblare trebuie sa arate asa:
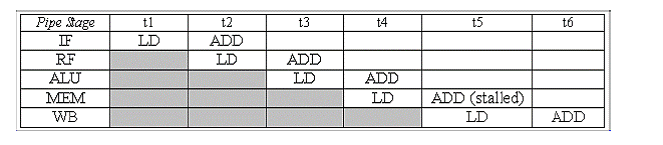
Intarzierea apare cand ADD si LD doresc sa acceseze stadiul WB in acelasi timp, si de aceea instructiunea ADD este fortata sa astepte in timpul t5.
D. Ideea celor de la P-R-U a imbunatatit performanta? Justificati.
Daca s-ar executa numai instructiuni ce necesita 4 stadii ca de exemplu ADD, autnci ideea celor de P-R-U ar fi imbunantit latenta cu 20%. In realitate, sunt executate programe cu multe instructiuni. Daca aceste instructiuni ar necesita numai 4 stadii, atunci, dupa cum a fost aratat in A., imbunatatirea ar fi fost semnficativa. Daca insa instructiunile ce necesita 4 stadii alterneaza cu cele care necesita 5 stadii, imbunatatirea nu are efect.
Problema 8:
Bargain Betas Inc. este o firma specializata in vanzarea de procesoare usor defecte, clientilor cu buget redus, capabili sa programeze, pentru evitarea defectelor. BBI a cumparat drepturile asupra designului Buba, o versiune cu mici defecte a procesorului Beta cu banda de asamblare cu 5 etaje. Singura diferenta este faptul ca nu are logica de ocolire sau anularea canalului de intarziere in cazul instructiunii Branch.
Se incearca executia a 3 mici secvente de cod pe procesorul Buba, incepand in fiecare caz cu R1=-1, R2=1, R3=5 si R4=-1.
S1: ADD(R1, R2, R3)
SUB(R2, R3, R4)
CMPLT(R3, R4, R5)
S2: ADD(R1, R2, R3) NOP SUB(R2, R3, R4) NOP CMPLT(R3, R4, R5)
S3: ADD(R1, R2, R3)
NOPSUB(R2, R3, R4)
CMPLT(R3, R4, R5)
A. Pentru fiecare din secventele de mai sus, spuneti (i) ce valoare se gaseste in R5 dupa executia pe un procesor Beta fara erori, si (ii) ce valoare se gaseste in R5 dupa executia pe un procesor Buba.
Pe procesorul Buba, cu banda de asamblare cu 5 etaje fara ocolire logica, rezultatul unei instructiuni nu va fi disponibil pentru citire (in stadiul RF) decat dupa 4 cicluri de ceas complet. Asadar, daca o anumita instructiune scrie o valoare in R0, acea valoare nu poate fi utlizata de urmatoarele 3 instructiuni (ele vor citi valoarea anterioara a lui R0). Cea de-a 4-a instructiune (ce urmeaza dupa instructiunea originala), este prima care citeste noua valoare a lui R0. Deci sa consideram urmatoarea secventa de cod:
ADDC(R31, 10, RO)
SUBC(R0, 5, R1)
ANDC(R0, 6, R2)
ORC(R0, 7, R3)
CMPLTC(R0, 11, R4)
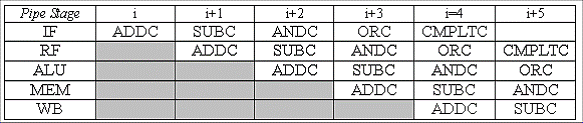
CMPLTC va fi prima instructiune care va lua noua valoare a lui R0. Toate Instructiunile anterioare folosesc valoarea precedenta a lui R0. Instructiunea ADDC este in stadiul WB, in timp ce ORC este in stadiul RF, deci noua valoare a lui R0 nu este scrisa la timp pentru ca ORC sa o citeasca.
Pentru Beta original, S1, S2 si S3 dau acelasi rezultat.
ADD( R1, R2, R3 ) Reg[ R3 ] = Reg[ R1 ] + Reg[ R2 ] = (-1) + 1 = 0
SUB( R2, R3, R4 ) Reg[ R4 ] = Reg[ R2 ] -Reg[ R3 ] = 1 -0 = 1
CMPLT( R3, R4, R5 ) Reg[ R5 ] = (Reg[ R3 ] < Reg[ R4 ]) = (0 < 1) = 1
Asadar, Reg[R5]=1 in toate cele 3 cazuri.
Pentru Buba (literele in italic ilustreaza cazul cand Buba difera fata de un procesor Beta original, in care rezultatul calculat cel mai recent nu este utilizat).
Pentru procesorul Buba:
S1:
ADD( R1, R2, R3 ) Reg[ R3 ] = Reg[ R1 ] + Reg[ R2 ] = (-1) + 1 = 0
Noua valoare a lui Reg[R3] nu este inca disponibila
SUB( R2, R3, R4 ) Reg[ R4 ] = Reg[ R2 ] -Reg[ R3 ] = 1 -5 = -4
Noile valori ale Reg[ R3 ] si Reg[ R4 ] nu sunt inca disponibile
CMPLT( R3, R4, R5 ) Reg[ R5 ] = (Reg[ R3 ] < Reg[ R4 ]) = (5 < -1) = 0
Reg[ R5 ] = 0
S2:
ADD( R1, R2, R3 ) Reg[ R3 ] = Reg[ R1 ] + Reg[ R2 ] = (-1) + 1 = 0NOP
Noua valoare a lui Reg[R3] nu este inca disponibila
SUB( R2, R3, R4 ) Reg[ R4 ] = Reg[ R2 ] -Reg[ R3 ] = 1 -5 = -4 NOP
Noua valoare a lui Reg[ R4 ] nu este disponibila inca (dar Reg[ R3 ] este)
CMPLT( R3, R4, R5 ) Reg[ R5 ] = (Reg[ R3 ] < Reg[ R4 ]) = (0 < -1) = 0
Reg[ R5 ] = 0
S3:
ADD( R1, R2, R3 ) Reg[ R3 ] = Reg[ R1 ] + Reg[ R2 ] = (-1) + 1 = 0 NOP
Noua valoare a lui Reg[R3] nu este inca disponibila
SUB( R2, R3, R4 ) Reg[ R4 ] = Reg[ R2 ] -Reg[ R3 ] = 1 -5 = -4
Noile valori ale Reg[ R3 ] si Reg[ R4 ] nu sunt inca disponibile
CMPLT( R3, R4, R5 ) Reg[ R5 ] = (Reg[ R3 ] < Reg[ R4 ]) = (5 < -1) = 0
Reg[ R5 ] = 0
B. Descrieti cum sa adaugati logica de intarziere minima procesorului Buba, astfel incat valoarea corecta sa fie plasata in R5 dupa completarea secventei S2.
Pentru a functiona S2 corect, trebuie sa adaugam logica de intarziere pentru ca rezultatul operatiei de ADD sa fie disponibil si pentru operatia de SUB. ADD este cu doua instructiuni inaintea SUB, deci ADD va fi in etapa MEM care se intinde pana la operandul B in etapa RF. Mai avem nevoie si de rezultatul instructiunii SUB pentru CMPLE, dar aceasta se poate face folosind aceeasi logica.
C. Descrieti ce cai de ocolire sunt necesare pentru a obtine rezultate corecte in toate cele 3 cazurile.
S-a discutat deja de ce este nevoie pentru S2.
Pentru S1:
Rezultatul operatiei ADD trebuie propagat urmatoarei operatii de SUB; este nevoie de ocolire: de la outputul lui ALU in etapa ALU la operandul B in etapa RF.
Rezultatul operatiei SUB trebuie propagat urmatoarei operatii de CMPLE; este nevoie de ocolire: de la outputul lui ALU in etapa ALU la operandul B in etapa RF.
Rezultatul operatiei ADD trebuie sa fie transmis instructiunii CMPLT (doua cicluri mai tarziu); este nevoie de ocolire: de la outputul ALU din etapa MEM la operandul A din etapa RF.
Pentru S3:
Rezultatul operatiei ADD trebuie sa fie transmis instructiunii SUB, la doua cicluri distanta; este nevoie de ocolire: de la outputul ALU din etapa MEM la operandul B din etapa RF.
Rezultatul operatiei SUB trebuie sa fie transmis urmatoarei instructiuni CMPLT; este nevoie de ocolire: de la outputul ALU in etapa ALU la operatorul B in etapa RF.
Rezultatul operatiei ADD trebuie sa fie transmis instructiunii CMPLT, trei cicluri mai tarziu; este nevoie de ocolire: de la outputul ALU in etapa WB la operandul A in etapa RF.
In total, este nevoie de 4 cai de ocolire:
outputul ALU din stadiul ALU la operandul B in stadiul RF
outputul ALU din estadiul MEM la operandul A in stadiul RF
outputul ALU din stadiul MEM la operandul B in stadiul RF
outputul ALU din stadiul WB la operandul A in stadiul RF
D. Adaugati numarul minim de NOP necesari urmatoarelor instructiuni pentru a produce rezultate identice pe procesorul Buba cu cele de pe procesorul Beta:
ADD(R3, R4, R5)
SUB(R5, R6, R7)
ADD(R1, R2, R3)
MUL(R7, R1, R2)
ADD(R4, R3, R5)
CMPLE(R7, R8, R9)
DIV(R7, R8, R10)
BEQ(R5, done)
ADDC(R1, 1, R5)
ADD( R3, R4, R5 )
NOP
NOP
NOP | Reg[R5] nu a fost actualizat inca
SUB( R5, R6, R7 )ADD( R1, R2, R3 )
NOP
NOP | Reg[R7] nu a fost actualizat inca
MUL( R7, R1, R2 )
ADD( R4, R3, R5 )
CMPLE( R7, R8, R9 )
DIV( R7, R8, R10 )
NOP | Reg[R5] nu a fost actualizat inca
BEQ( R5, done )
NOPADDC( R1, 1, R5 )
Problema 9:
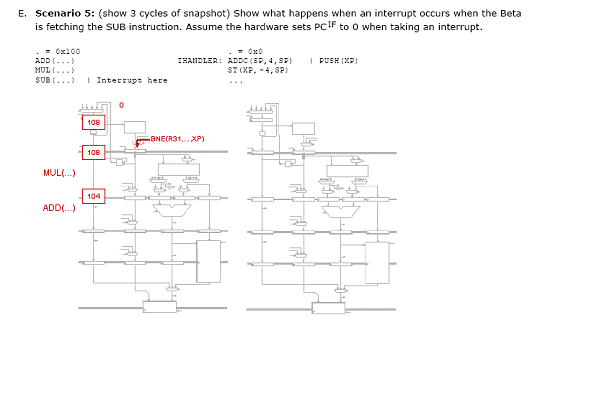
Aceasta problema face referire la intreruperile externe ale procesorului Beta, avand o structura de banda de asamblare cu 5 etaje, cu ocolire, si cu un canal de intarizere in cazul instruciunii Branch, cu anulare ( instructiunea din canalul de intarziere nu este executata). De luat in considerare este faptul ca daca o intrerupere externa are loc in ciclul I, atunci adresa rutinei de tratare a intreruperilor, XAdr, este incarcata in PC la sfarsitul ciclului I, iar instructiunea ce ocupa nivelul IF in timpul ciclului I, va fi inlocuita cu BNE (R31, XAdr, XP). Sa presupunem ca acestea ar fi primele linii ale unei rutine de tratare a intreruperilor:
XAdr: ADDC (SP, 4, SP)
ST (R0, -4, SP)
.
Mai intai, sa consideram acest fragment de cod:
. = 0x1234
start : CMPLTC(R1, 0, R2)
SUB (R3, R2, R3)
XOR (R0, R3, R0)
MUL (R1, R2, R3)
SHLC (R1, 2, R4)
A Completati urmatoarea diagrama pentru cazul executiei normale a acelor instructiuni (nu au loc intreruperi) :
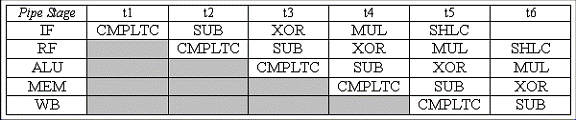
B. Completati urmatoarea diagrama presupunand ca o intrerupere apare in ciclul t2. Ce valoare este salvata in XP ca rezultat al intreruperii? Unde ar trebui rutina de tratare a intreruperilor sa se intoarca atunci cand ea se incheie? De ce nu se intoarce aceasta la instructiunea a carei adresa este salvata in XP ?
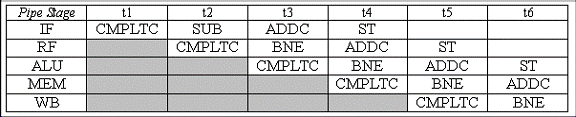
Intreruperea cauzeaza retinerea adresei 0x123C in XP. Cand rutina de tratare a instructiunilor se incheie, aceasta ar trebui sa se intoarca la instructiunea SUB la 0x1238. Daca s-ar intoarce la adresa stocata in XP, atunci instructiunea SUB nu s-ar mai executa niciodata, pentru ca nu a fost executata inainte de inceperea rutinei de tratare a intreruperilor.
C. Acum sa consideram ce se intampla daca includem o instructiune Branch in secventa de instructiuni :
skip : BR(NEXT)
CMPLTC(R1, 0, R2)
ADD(R3, R2, R3)
next: XOR(R0, R3, R0)
MUL(R1, R2, R3)
SHLC(R1, 2, R4)
Completati diagrama pentru o executie normala a instructiunilor incepand de la skip :

D. Completati diagrama presupunand ca o intrerupere apare in ciclul t2. La ce instructiune se va intoarce rutina de tratare a intreruperilor, cand aceasta se va termina ? De ce reprezinta aceasta o problema ?
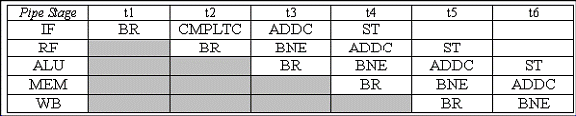
Dupa ce rutina de tratare a instructiunilor se termina, se va intoarce la instructiunea CMPLTC. Aceste nu este cu siguranta un comportament corect, deoarece noi dorim ca instructiunea Branch sa fie luata in considerare si CMPLTC sa fie anulata.
E. Intreruperile normale sunt tratate in cadrul ciclului in care apar. Instructiunea de la nivelul IF este inlaturata si o ramificatie este fortata catre locatia Xadr. Presupunem insa ca dispozitivul hardware poate fi schimbat astfel incat in unele cazuri intreruperile sa nu fie tratate in ciclul in care ele au aparut. In particular, presupunem ca nu este permisa aparitia intreruperilor cand se anuleaza o instructiune intr-un canal de intarziere in cazul instructiunii Branch. Explicati cum rezolva aceasta, problema evidentiata la subpunctul D.
Prin interzicerea intreruperilor atunci cand se anuleaza canalul de intarziere in cazul instructiunii Branch (ciclul t2), valoarea PC+4 care se stocheaza in XP cand intreruperile sunt tratate (ciclul t3), este adresa celei de-a doua instructiuni dupa Branch, care, in cazul exemplului nostru, este instructiunea MUL. La revenirea din rutina de tratare a intreruperilor, XP va fi adaptata la adresa instructiunii XOR.
F. Presupunand ca aparitia intreruperilor nu este permisa atunci cand se anuleaza o instructiunea intr-un canal de intarziere in cazul instructiunii Branch, va crea programul urmator o bucla care nu poate fi intrerupta ?
X : BR(Y)
Y : BR(X)
Nu. Secventa poate fi intrerupta. Daca intreruperea soseste in decursul ciclului t2, si noi am dezactivat intreruperile in timpul anularii canalului de intarziere in cazul instructiunii Branch, atunci intreruperea va fi tratata in timpul ciclului t3.
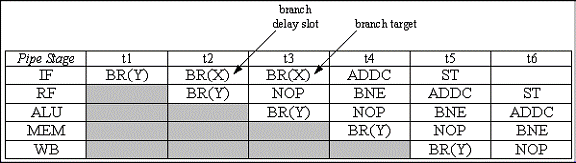
Adresa stocata in XP este instructiunea ce urmeaza dupa BR(X), iar la revenirea din rutina de tratare a intreruperilor, XP este adaptata la adresa lui BR(X). Un argument similar poate fi adus daca intreruperea soseste in timpul anularii intarzierii instructiunii BR(X).
Bibliografie:
https://csit-sun.pub.ro/courses/
https://6004.csail.mit.edu/currentsemester/handouts/L23-4up.pdf
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2945
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2026 . All rights reserved