| CATEGORII DOCUMENTE |
| Comunicare | Marketing | Protectia muncii | Resurse umane |
TEHNOLOGII MODERNE DE EXPLORARE SI EXPLOATARE A DATELOR
1. Depozite de date (Data Warehouse)
Depozitul de date (Data Warehouse) este un sistem complex care contine datele operationale si istorice ale unei organizatii, fiind o entitate separata de celelalte baze de date operationale. Cantitatea enorma de date continute de un depozit de date provine atat din surse interne cat si din sursele externe ale organizatiei. Depozitul de date preia datele din bazele de date operationale, urmand ca asupra lor sa se realizeze diferite analize in scopul sprijinirii decidentului in cadrul procesului decizional.
Conform lui W.H. Inmon, cel mai de seama autor in domeniul construirii depozitelor de date, acestea sunt "o colectie de date orientate pe subiecte, integrate, istorice si nevolatile destinata sprijinirii procesului decizional", de aici rezultand caracteristicile depozitelor de date: orientarea pe subiecte, integrarea, caracterul istoric si persistenta datelor.
Procesul de construire si utilizare al depozitelor de date este cunoscut sub denumirea data warehousing, iar acest proces presupune integrarea, filtrarea si consolidarea datelor.
Obiectivele aferente unui depozit de date au fost identificate ca fiind urmatoarele:
Ø asigurarea accesului sporit la date pentru utilizator - un calculator este cel care faciliteaza accesul utilizatorului la depozitul de date;
Ø oferirea unei singure versiuni a datelor - utilizatorului nu i se pun la dispozitie date ambigue, fara sa mai existe nici dezbateri cu privire la veridicitatea datelor utilizate;
Ø inregistrarea si redarea cu acuratete a trecutului - datele din trecut pot fi extrem de importante pentru utilizatori, deoarece deseori datele din prezent nu sunt relevante daca nu se compara cu cele din trecut;
Ø permiterea accesului combinat sinteza/detaliu la date - informatiile se pot colecta si formata cu mai multa usurinta utilizand datele din cadrul depozitelor de date;
Ø diferentierea prelucrarilor la nivel operational si analitic - intretinerea unui sistem informational in cadrul caruia informatiile decizionale si cele operationale trebuie reunite este problematica.
Depozitele de date contin diferite tipuri de date: date detaliate, date agregate, metadate, acestea din urma sunt cele ce permit specificarea structurii datelor, provenienta lor, regulile de transformare, fiind utilizate in cadrul incarcarii datelor si avand astfel un rol important in alimentarea depozitului de date. Arhitectura depozitului de date este prezentat in Figura 1.
![]()
![]()

![]()
![]()
![]()
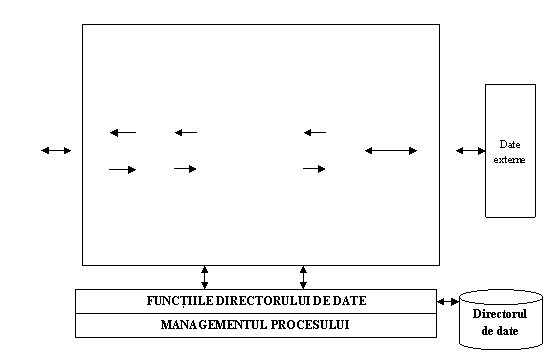

Figura 1. Arhitectura generala a depozitului de date
Utilizarea depozitelor de date are o serie de avantaje, din care mentionam urmatoarele:
decidentii pot obtine cu mai mare usurinta o serie de rapoarte in spijinul procesului decizional;
cresterea consistentei datelor, a "productivitatii" acestora;
utilizatorii au acces la o mare varietate de date;
structura depozitului de date face ca aceasta sa se adapteze cu usurinta la schimbarile datelor si sa fie capabila sa transmita datele modificate sistemului operational.
O alta entitate asemanatoare cu depozitul de date este Data Mart, des intalnita in literatura de specialitate si care a generat indelungi discutii cu privire la faptul ca aceasta este sau nu echivalenta cu un depozit de date. Data Mart nu este echivalent cu depozitul de date, este o colectie de date pe domenii de interes in functie de nevoile unui anumit departament al organizatiei. Exista Data Mart pe parte financiara, pe parte de marketing etc., acestea fiind aproape in totalitate independente unele de altele. Fiecare departament este considerat a fi proprietarul componentelor hardware si a componentelor software ce constituie Data Mart.
Data Mart sunt de doua tipuri: dependente si independente. Un Data Mart dependent este acela a carui sursa este depozitul de date, iar cel independent este cel a carui sursa o constituie propriile aplicatii.
Data Mart dependente sunt cele care iau forma in urma incarcarii datelor din cadrul sistemelor operationale, in depozitul de date al organizatiei care va fi subdivizat in unitati mai mici denumite Data Mart, iar dependenta acestora e determinata tocmai de faptul ca sunt derivate din depozitele de date.
Data Mart independente sunt mai instabile decat cele dependente, iar deficientele pe care acestea le au determina ca ele sa nu se manifeste pana in momentul in care in cadrul organizatiei exista mai multe Data Mart independente. Intrucat organizatiile se dezvolta pe parcurs, se ajunge la situatii in care avem de-a face cu mai multe Data Mart ce au luat amploare si care necesita, fiecare in parte, preluarea de date din cadrul bazelor de date operationale, fapt care poate deveni relativ costisitor, dar si ineficient pentru respectivele baze de date operationale, deoarece se reduce timpul dedicat lucrului pentru care sunt destinate in favoarea furnizarii datelor catre Data Mart.
Depozitele de date pot fi deosebit de utile diferitelor categorii de decidenti, iar principalele moduri in care se beneficiaza de datele din cadrul depozitelor de date sunt solutiile de procesare analitica on-line (OLAP) si tehnicile Data Mining.
2. Tehnologii de procesare analitica a datelor on line (OLAP)
Tehnologia OLAP se refera la posibilitatea de agregare a datelor din cadrul unui depozit de date, avand capacitatea de a obtine din volumul mare de date informatii utile procesului decizional din cadrul unei organizatii. Conform specialistilor, un termen alternativ care ar fi mai reprezentativ pentru descrierea conceptului OLAP ar fi FASMI (Fast Analysis of Shared Multidimensional Information - Analiza rapida a informatiilor partajate multidimensionale). Esenta oricarui sistem OLAP este cubul OLAP, cunoscut si sub denumirea de cub multidimensional, format din fapte numerice numite masuri, categorisite dupa dimensiuni [wikipedia]. Aceste masuri rezulta din articolele tabelelor din cadrul bazelor de date relationale. Rezultatele cerintelor utilizatorilor pot fi obtinute prin parcurgerea dinamica a dimensiunilor cubului de date, la diferite niveluri de sinteza sau detaliere.
Sistemele OLAP au urmatoarele caracteristici[Zaharie01]:
Ø perspectiva multidimensionala asupra datelor;
Ø capacitate de calcul intensiv;
Ø orientarea in timp (time intelligence).
Tehnologiile disponibile pentru gestionarea datelor si informatiilor trebuie sa contribuie la o mai buna intelegere a trecutului si la previzionarea viitorului prin intermediul eficientizarii deciziilor luate, aici intervenind tehnologiile Data Mining. Tehnologiile Data Mining integrate in sistemele de asistare a deciziilor determina existenta unui instrument de asistare a deciziilor bazat inca pe interactiunea om-masina (om-sistem de calcul), iar aceste doua entitati luate impreuna reprezinta un spectru de tehnologii informatice analitice care realizeaza o platforma pentru o combinatie optima pentru o analiza dictata de date, dar condusa de om [Ganguly05].
In cadrul sistemului de asistare a deciziilor utilizat intr-o organizatie puternic informatizata se regasesc elementele din Figura 2. Totusi, in functie de sistem, de complexitatea si functionalitatea acestuia, elementele mentionate pot fi sau nu prezente.
![]()
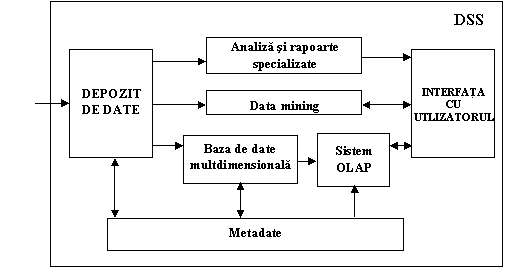

Figura 2. Componentele unui sistem de asistare a deciziilor intr-o organizatie
puternic informatizata
3. Data Mining - tehnologii avansate de procesare a datelor
Tehnologiile Data Mining poseda caracteristici datorita carora sunt potrivite pentru analizarea cantitatilor foarte mari de date. Data Mining are ca scop descoperirea de sabloane in cadrul seturilor de date, in timp ce alte tehnologii analitice, cum ar fi interogarile, pachetele pentru analiza statistica, uneltele OLAP, sunt bazate pe verificari, care se dovedesc a fi limitate.
Colectionarea datelor ce reflecta activitatile unei organizatii a devenit vitala pentru dobandirea avantajului competitional. Companiile mijlocii si mari au investit in sisteme informatice care colectioneaza date si gestioneaza baze de date foarte mari. Sarcina esentiala pe care aceste sisteme o duc cu succes la indeplinire este extragerea de cunostinte in urma rationamentelor efectuate asupra informatiilor rezultatelor din cadrul datelor colectionate.
Cantitatea enorma de date depaseste cu mult capacitatea umana, prin urmare pentru ca deciziile manageriale sa fie fundamentate corect, este necesara existenta de sisteme ce utilizeaza tehnologia Data Mining. Acestea permit stabilirea de sabloane chiar date brute, neprocesate, furnizand diferite rezultate ce pot fi utilizate atat in sistemele de asistare a deciziei sau pot fi de ajutor analistului uman.
Procesul de Data Mining cuprinde patru faze importante: colectarea datelor, pregatirea datelor, stabilirea unor sabloane si analiza acestor sabloane. Faza de colectare a datelor implica preluarea de date din diferite surse, iar cum aceste date pot fi eterogene, faza de pregatire a datelor presupune normalizarea acestora si reprezentarea lor in structuri in asa fel incat sa devina mai usor de utilizat. Datele identificate dupa anumite caracteristici in faza anterioara sunt extrase si apoi formatate pentru a reprezenta datele in formatul pe care aplicatia de Data Mining o solicita. Datele odata pregatite si formatate, se aplica tehnicile de Data Mining pentru a fi stabilite sabloanele.
Sistemele informatice bazate pe tehnologii Data Mining au evoluat, in prezent fiind capabile "sa invete" din comportamentul anterior al elementelor cercetare, si pe baza cunostintelor dobandite in urma "procesului de invatare" formuleaza ipoteze pe care le testeaza. Cunostintele ce se dovedesc a fi valide si utile pot fi integrate in sisteme de asistare a deciziei care vin in sprijinul decidentilor, in scopul de a le fi de folos in luarea deciziilor fundamentate.
Cateva din beneficiile pe care tehnologiile Data Mining le pot oferi in afaceri sunt:
Ø identificarea celor mai bune strategii de marketing;
Ø previzionarea interesului unui anumit client pentru diverse produse;
Ø identificarea si asimilarea parametrilor ce influenteaza tendintele in vanzari;
Ø asista procesul de segmentare a pietei si personalizarea comunicarii cu clienti tinta.
Necesitatea, popularitatea si utilitatea tehnologiilor Data Mining se afla in continua crestere din urmatoarele motive:
cresterea volumului de date acumulat zilnic de o organizatie poate fi coplesitor;
limitarea analistilor umani, a caror capacitate de analiza este cu mult depasita de volumul imens de date si complexitatea determinata de dependentele dintre date, in plus, interventia umana implicand si un deficit de obiectivitate in analiza;
costurile reduse ale sistemelor automate de Data Mining, fata de costurile pe care le-ar implica numarul mare de specialisti umani care cu greu ar face fata acelorasi sarcini, cu precizarea ca Data Mining nu elimina in totalitate implicarea partii umane, ci simplifica sarcina acestuia si permite unui analist care nu e un specialist in statistica si programare sa obtina cunostintele necesare.
Fara a intra in detalii, sarcini ce pot fi indeplinite de tehnologiile Data Mining sunt:
predictia - predictia unor valori viitoare ale unor variabile de interes se poate obtine urmarind sabloane din exemple si dezvoltand un model;
clasificarea - presupune gasirea unei functii ce clasifica inregistrarile in clase discrete;
detectarea relatiilor - este o sarcina ce permite cautarea celor mai influente variabile independente;
modelarea explicita - permite gasirea unor formule explicite ce descriu dependentele dintre diferite variabile;
clustering - permite identificarea de grupuri de articole ce prezinta asemanari si sunt diferite fata de alte articole.
Data Mining permite stabilirea sabloanelor din date, utilizand tehnici de predictie. Aceste sabloane dovedesc o mare importanta in procesul decizional deoarece evidentiaza aspecte ce pot duce la imbunatatirea procesului decizional, atat din punct de vedere al eficientei, cat si din considerente de timp. Imbunatatirea managementului riscului, profitabilitatea unei organizatii in urma interactiunii cu clientii sai pot creste datorita utilizarii Data Mining.
In ceea ce priveste sistemele software pentru Data Mining, acestea au fost impartite in doua categorii: unelte Data Mining si aplicatii Data Mining. Uneltele Data Mining ofera tehnici de pot fi aplicate oricarei probleme sau situatii de afaceri. Aplicatiile Data Mining sunt cele ce "incapsuleaza" tehnicile Data Mining in cadrul unei aplicatii destinata unei probleme specifice din domeniul afacerilor. Aceasta separare nu inseamna ca una dintre aceste categorii este mai putin importanta si necesita mai putina atentie din partea organizatiilor.
Uneltele Data Mining trebuie sa asigure o anume flexibilitate si cea mai mare acuratete posibila, pentru a imbunatati eficacitatea aplicatiilor Data Mining. Intrucat organizatiile se deosebesc intre ele in mod firesc, si datele existente in cadrul lor difera, prin urmare e dificil de stabilit o tehnica ce ar duce la cele mai bune rezultate pentru orice organizatie. Uneltele Data Mining sunt flexibile din acest punct de vedere si permit combinarea tehnicilor pentru a imbunatati acuratetea rezultatelor dorite.
In mediul de afaceri, proiectele Data Mining de mare complexitate vor necesita coordonarea si implicarea expertilor si persoanelor interesate din toate departamentele organizatiei. In literatura preocupata de domeniul Data Mining s-a incercat elaborarea si propunerea unor modele pentru stabilirea modului de organizare a procesului de colectare a datelor, de analiza a datelor, diseminarea rezultatelor, implementarea rezultatelor, si in sfarsit, monitorizarea imbunatatirilor.
Modelul CRISP (Cross-Industry Standard Process for data mining) a fost propus in anii '90 de catre un consortiu format din doua companii europene si a devenit un model standard pentru Data Mining. In urma acestui mod de abordare generalizat, s-a stabilit o secventa de pasi de urmat in proiectele Data Mining.


Figura 3. Ciclul de viata al proiectelor Data Mining
Ciclul de viata al unui proiect de Data Mining este format din sase faze (Figura 3). Sagetile dintre faze sugereaza cele mai frecvente si importante dependente dintre faze, dar deseori este necesara trecerea in una din directii intre faze, in functie de rezultatul fiecarei faze si de sarcina ce trebuie indeplinita in continuare.
Faza de formulare a situatiei de afaceri presupune intelegerea obiectivitatii si cerintelor proiectului din perspectiva domeniului de afaceri respectiv, apoi convertirea cunostintelor si formularea problemei de Data Mining, si in final realizarea unui plan preliminar pentru atingerea obiectivelor stabilite.
Urmatoarea faza este cea de restrictionare a datelor, care porneste cu o colectie initiala de date si continua cu activitati de acomodare cu respectivele date, identificarea problemelor de calitate legate de date, descoperirea primelor informatii din date sau detectarea unor subseturi din care se pot forma ipoteze pentru descoperirea informatiei.
Faza de pregatire a datelor se refera la toate activitatile pentru construirea setului final de date, care va fi utilizat de uneltele de modelare, din cadrul datelor brute initiale. Aceasta faza e recomandat sa fie parcursa de mai multe ori, si include selectarea tabelelor, inregistrarilor si transformarea, respectiv filtrarea datelor pentru uneltele de modelare.
Modelarea este faza in care diferite tehnici de modelare sunt selectate si aplicate, iar parametri sunt adusi la valori optime. Deseori este necesara intoarcerea la faza de pregatire a datelor, deoarece unele din tehnicile utilizate au anumite cerinte legate de forma datelor.
Faza de evaluare indica momentul in care este disponibil modelul construit. Inainte de extinderea modelului, acesta trebuie evaluat si trebuie verificati pasii executati pentru construirea modelului, pentru a se asigura ca atinge obiectivele propuse.
Extinderea este o faza ce poate avea ca finalitate generarea unui raport sau implementarea unui proces repetabil de Data Mining. De regula nu analistul de date, ci clientul proiectului va realiza faza de extindere, motiv pentru care clientul va trebui sa inteleaga foarte bine ce trebuie sa faca pentru utilizarea corecta a modelelor create.
Data Mining, utilizand algoritmi Machine Learning, este tehnica de a descoperi relatii, denumite sabloane, in colectiile de date, utilizandu-le pentru realizarea unor noi reguli si pentru predictia comportamentelor viitoare - reusind sa transforme cantitatea imensa de date in cunostinte valoroase ce duc la oportunitati nebanuite in afaceri.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2297
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2026 . All rights reserved